
Te presento algunas situaciones clave que un ingeniero DevOps debe conocer usando Terraform. Son errores comunes y proporciona orientación para evitar problemas de infraestructura y garantizar implementaciones más fluidas.
¿Qué pasa si pierdes acceso al backend remoto donde se almacena el estado de Terraform?
Si pierdes acceso, podrías quedar completamente incapacitado para administrar tu infraestructura. Para evitarlo, configura controles de acceso robustos y planes de respaldo.
¿Qué pasa cuando superas los límites establecidos por AWS durante una implementación?
Terraform falla los recursos y deja el despliegue a medias. Revisa tus cuotas antes de desplegar a gran escala.
| Verificación previa de cuotas | Solicitud de aumento de cuotas | Ajustar despliegue |
| Garantiza que no se excedan las cuotas, previniendo problemas en el despliegue | Busca aprobación para incrementar límites y permitir despliegues mayores | Redimensionar implementación. Cumple con cuotas existente |
¿Qué ocurre si tus módulos de Terraform tienen dependencias circulares?
¡Bucle infinito catastrófico! Terraform se bloquea mostrando errores de dependencias circulares. Solución: Reorganiza tus módulos para eliminar las referencias cruzadas.
¿Qué ocurre si la API de un proveedor cambia entre versiones de Terraform?
¡Error: Conflicto de versiones! Riesgo de fallos o recreación de recursos. Prueba en staging antes de actualizar.
Para evitar problemas:
Usa terraform plan para detectar cambios drásticos antes de aplicar.”
Fija versiones explícitas en tu required_providers.
Revisa los registros de cambios (changelogs) del proveedor.
¿Qué sucede si eliminas un recurso de tu configuración de Terraform?
Increiblemete suele pasar. En el próximo apply, Terraform lo destruirá a menos que lo elimines manualmente del estado [terraform state rm]. Usa prevent_destroy para evitar eliminaciones accidentales.
“Si quitas un recurso del archivo .tf pero no del estado (state):
Terraform lo destruirá en el próximo apply (asume que ya no es necesario).
Solución 1: Elimínalo manualmente del estado con terraform state rm .
Solución 2: Usa lifecycle { prevent_destroy = true } para proteger recursos críticos.”
# Ejemplo de cómo proteger un recurso:
resource "aws_instance" "servidor_critico" {
ami = "ami-123456"
instance_type = "t2.micro"
lifecycle {
prevent_destroy = true # ¡Evita que Terraform lo borre!
}
}
¿Qué pasa si se elimina tu archivo de estado (state file) de Terraform?
Terraform pierde el rastro de tus despliegues e intentará recrear todo desde cero, lo que puede generar conflictos y recursos duplicados. ¡Siempre haz backup de tu archivo de estado!
¿Por qué es grave?
Recursos duplicados: Terraform creará nuevos recursos (ej: servidores, bases de datos) aunque ya existan, lo que puede:
Aumentar costos (pagos por instancias adicionales).
Romper configuraciones (ej: direcciones IP conflictivas).
Imposibilidad de gestionar infraestructura existente: No podrás modificar o eliminar recursos ya desplegados.
Como medida de protección utiliza los servicios de aws S3 o GCS o Azure Blob
terraform {
backend "s3" {
bucket = "nombre-de-tu-bucket"
key = "ruta/al/estado.tfstate"
region = "us-east-1"
}
}
Habilita bloqueo de estado (evita corrupción por ejecuciones simultáneas):
backend "s3" {
dynamodb_table = "terraform-locks" # Tabla DynamoDB para bloqueo
}
Backups manuales (para paranoicos):
terraform state pull > estado_backup_$(date +%F).json
Si ya ocurrió el desastre…
Recupera desde backup (si tienes uno).
Reimporta recursos manualmente (con terraform import).
Limpia recursos huérfanos (vía consola de AWS/Azure/GCP).
¿Qué pasa si dos equipos ejecutan terraform apply al mismo tiempo?
Conflicto en el archivo state – Sin un bloqueo adecuado, Terraform puede corromper el estado, causando desviaciones impredecibles en la infraestructura. ¡Utiliza un estado remoto con bloqueo!
Si múltiples equipos ejecutan Terraform sin bloqueo (locking):
1) El archivo .tfstate puede dañarse
2) La infraestructura podría desviarse sin control
Solución: Configura un backend remoto (S3/GCS) con bloqueo automático”
¿Qué pasa si terraform plan no muestra cambios, pero alguien modificó la infraestructura manualmente?”
Terraform no notará cambios externos a menos que ejecutes terraform refresh. Futuros apply podrían sobrescribir modificaciones manuales sin advertencia. Terraform no los gestionará automáticamente. Siempre detecta desviaciones antes de aplicar.
Solución:
Forzar una sincronizacion
terraform refresh # Actualiza el estado con la infra real (pero ¡cuidado! Puede sobrescribir metadatos).
Recuperar el control:
Si los cambios manuales deben mantenerse, actualiza tu configuración (.tf) para reflejarlos.
Si son no deseados, usa terraform apply para volver al estado declarado.
Prevención (Mejores Practicas):
Bloquea entornos críticos (ej: con IAM para evitar cambios manuales).
Usa terraform import para añadir recursos manuales al estado.
Monitorea el drift: Herramientas como Terraform Cloud o Driftctl detectan cambios no gestionados.
¿Qué pasa si alcanzas los (rate limits) de AWS durante un despliegue?
Terraform reintenta algunas veces… pero luego falla. Los recursos ya creados quedan activos, dejándote con un despliegue a medias. Optimiza lotes y maneja reintentos inteligentemente.
Cuando las APIs de AWS devuelven errores de throttling (ej: RequestLimitExceeded):
1) Terraform reintenta 3-5 veces (por defecto), pero si persiste, aborta.
2) Los recursos ya desplegados no se rollbackean: Quedan activos pero sin configuración final.
3) Resultado: Infraestructura inconsistente (mitad aplicada, mitad fallida).
Soluciones:
Reduce el paralelismo: Limita la cantidad de operaciones concurrentes.
Aumenta reintentos: Configura max_retries en el provider AWS.
Divide en batches: Usa -target para aplicar módulos críticos primero.
provider "aws" {
region = "us-east-1"
max_retries = 10 # ↑↑↑ Aumenta reintentos (default: 5)
}
# Opcional: Limita operaciones concurrentes (para evitar throttling)
terraform {
parallelism = 5 # ↓↓↓ Reduce si AWS devuelve throttling (default: 10)
}
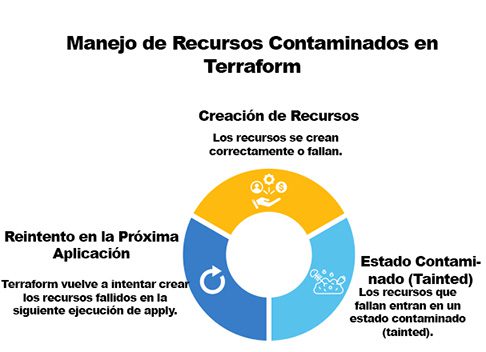
¿Qué pasa si terraform apply falla a medio camino?
Los recursos que se crearon correctamente permanecen activos, pero los que fallaron quedan en un estado contaminado (tainted). Terraform volverá a intentar crear los recursos fallidos en la próxima ejecución de apply. ¡Aprende cómo manejar los recursos contaminados!
Impacto inmediato:
Recursos “zombis”: Algunos recursos se crean, otros no → infraestructura inconsistente.
Estado corrupto: El archivo .tfstate puede quedar desincronizado de la realidad.
Bloqueo operativo: Dependencias rotas (ej: una VPC creada, pero sus subnets no).
¿Como Recuperarse?
- Diagnosticar:
terraform plan -refresh-only # Ver qué recursos existen vs. lo esperado
2. Decidir una estrategia:
a) Destruir lo desplegado (si es un entorno temporal): -> terrafrom destroy
b) Reparar Manualmente:
Recursos faltantes: Añádelos con terraform import .
Recursos corruptos: Elimínalos con terraform state rm y recrea.
3. Reintentar.
terraform apply -refresh-only # Primero sincroniza el estado terraform apply -target=aws_instance.example # Aplica solo recursos problemáticos
Un apply fallido no es el fin. Con backups, diagnóstico preciso y reparación dirigida, puedes recuperar el control. ¡Automatiza y prueba en staging

