Veamos paso a paso un Pipeline CI/CD para una aplicación. Veremos como se conectan las herramientas, desde el código hasta que la aplicación está funcionando. Es un poco extenso pero va muy detallado. Para que no te pierdas nada.
Estaremos utilizando 5 Instancias EC2 de AWS, aparte de las 3 Instancias que utilizará AWS EKS, para que lo tomes en cuenta.
Usaremos una aplicación Full Stack muy sencilla pero funcional. Cumple completamente con un CRUD, y usa H2 que es una base de datos en memoria.
Te muestro un diagrama y como comienza el flujo.
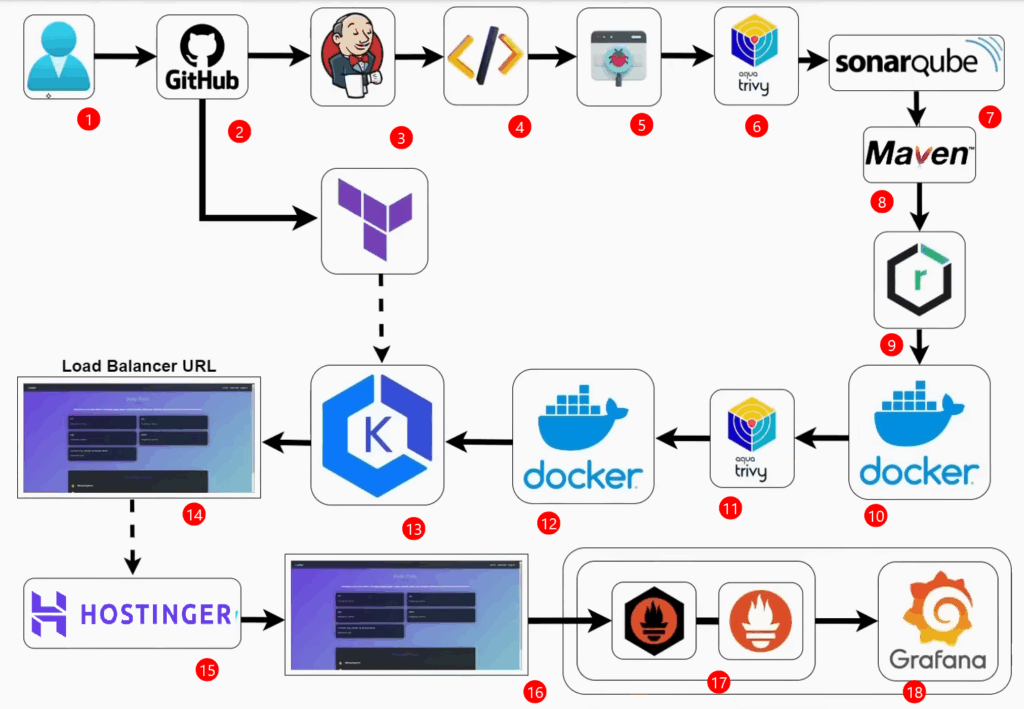
1) El desarrollador envía el código fuente (Java) al repositorio de Github.
2) Dentro de el repositorio de Github mantendremos el código fuente de la aplicación y el código terraform que se utilizará para crear el cluster de EKS
3) Una vez que se envíe el código, se activará el Pipeline de Jenkins (también se puede activar manualmente).
4) Después se compila el código fuente para detectar errores de sintaxis en el pipeline.
5) Pasamos a los Test Cases o casos de pruebas unitarios para ejecutar y probar el código.
6) Seguidamente utilizaremos Aqua Trivy para realizar un escaneo de vulnerabilidades en el código fuente de la aplicación, en el sistema de archivos y en las dependencias que se utiliza en el proyecto.
7) SonarQube para verificar la calidad de el código, detectar errores o cualquier tipo de problemas en el código.
8) Luego tenemos la herramienta Maven para compilar la aplicación y crear un ejecutable .jar (artefacto).
9) Una vez tengamos el .jar o el artefacto listo, se envia a Nexus Repository para almacenar el artefacto.
10) Se crea la imagen Docker de la aplicación y mantenemos la aplicación en el Docker Registry.
11) Se escanea la imagen de Docker para detectar algún tipo de error en la fuente de la imagen Docker.
12) Una vez que se compruebe a imagen Docker, se envía a Docker Registry privado.
13) Se implementa la aplicación en el cluster de Kubernetes configurado en EKS de AWS. Se configura un secret dentro de Kubernetes que tendrá las credenciales para acceder al registro privado de Docker. Una vez implementada la aplicación,
14) se obtiene una URL del balanceador de carga.
15) Se mapea el dominio usando Hostinger o Godaddy
16) Se accede a la aplicación usando el nombre de dominio.
17) Luego podremos monitorear la aplicación web usando Blackbox exporter Prometheus y Grafana blackbox exporter obtendrá las métricas, las reenviará a Prometheus y
18) eventualmente se compartirá con Grafana para presentarla en un formato fácil de visualizar.
Pasos:
- Configurar el Repositorio en Github
- Instalación de los servidores (Jenkins, SonarQube, Nexus, Monitoring Tools).
- Configuración de las herramientas.
- Crear o escribir el Pipeline y Crear el Cluster EKS.
- Activar el Pipeline para implementar la aplicación.
- Asignar el dominio a la aplicación.
- Monitorear la aplicación.
Iniciamos creando el repositorio privado en GitHub

Abrimos Git Bash y clonamos el repositorio en local

Si no estas logueado en Github te pedirá las credenciales.
Accedemos al proyecto y pegamos el código fuente de la aplicación.
En GitBash Ejecutamos git init
Ejecutamos git add .
Ejecutamos git commit -m “Subir Codigo Fuente” Ejecutamos
Ejecutamos git remote add origin https://github.com/richardaguirre1/full-stack-bloggin-app.git
Ejecutamos git push -u origin master
Revisamos en GitHub
Listo el Paso numero 1.
Vamos al Paso 2: Instalación de los servidores (Jenkins, SonarQube, Nexus, Monitoring Tools).
Si tienes un entorno local puedes instalar varias de estos servidores para ahorrar costos.
Sino, vamos a crear varias instancias EC2 en AWS de tipo t2.medium. Estas están fuera del free tier al momento de escribir estas líneas.
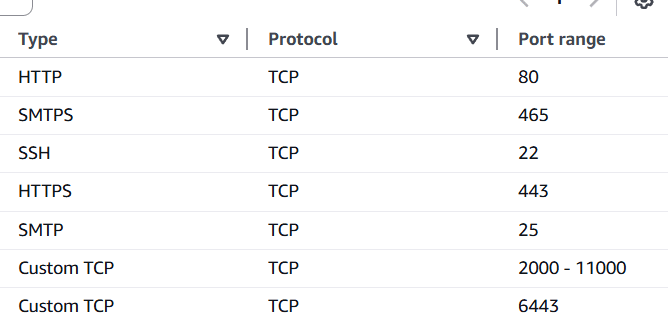
Go to AWS y creamos un Security Groups
Vamos a requerir, acceso al puerto SSH 22 , SMTP 25, SMTPS 465, HTTP 80, HTTPS 443, Custom TCP 2000 -11000, Custom TCP 6443.
Creamos 2 Instancias EC2 t2.medium con Ubuntu Server para SonarQube y Nexus.
Nexus requiere al menos 4 GB de Almacenamiento.
Recordemos crear un keyPair si no lo tenemos y asignarlo a estas Instancias EC2 y asignarle también el SG que creamos, así como también la VPC y las subred donde queremos tener nuestras instancias y que por su puesto tenga acceso a internet pública.
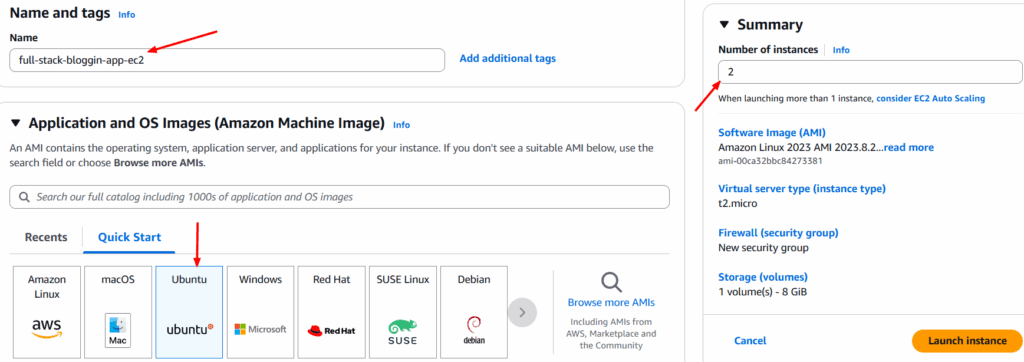
Una vez creadas las instancias EC2, podemos asignarles un nombre como SonarQube y Nexus.
Creamos otra Instancia EC2 para Jenkins, esta vez de tipo t2.large, con Ubuntu Server, almacenamiento al menos 25 GB.

Accedemos a las instancias EC2 por ssh con la ip publica de cada instancia y la Key publica. Podemos utilizar MobaXterm o cualquiera que le guste.
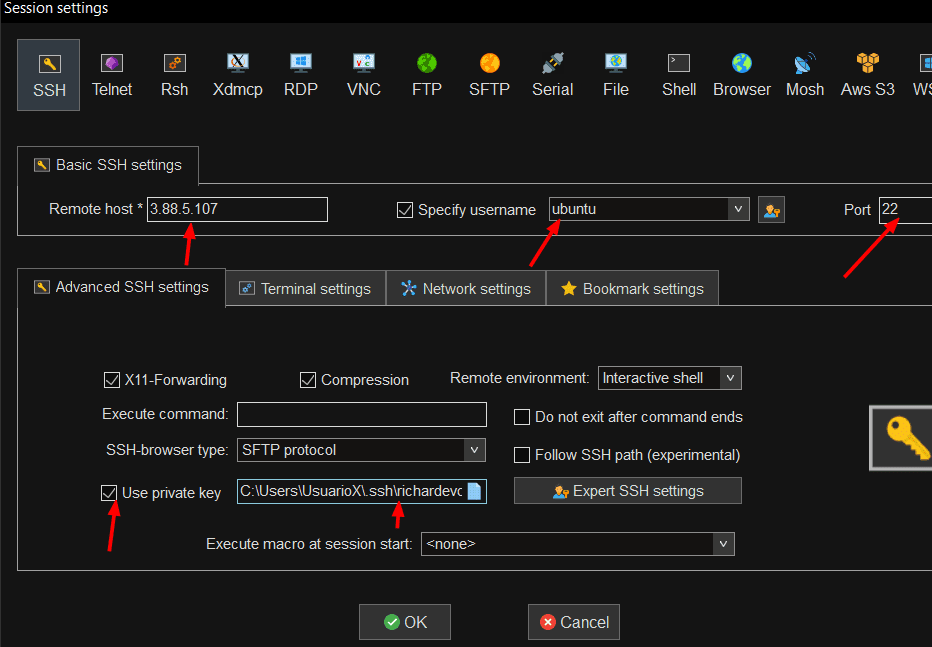

Tenemos las 3 Instancias conectadas por ssh al mismo tiempo.
En las 3 ejecutamos
sudo apt update
En la Instancia Jenkins debemos tener instalado java
Usaremos java17 (depende de los requerimientos)sudo apt install openjdk-17-jre-headless -y
E instalamos Jenkins para Ubuntu con estos comandos:
sudo wget -O /etc/apt/keyrings/jenkins-keyring.asc \ https://pkg.jenkins.io/debian-stable/jenkins.io-2023.key echo "deb [signed-by=/etc/apt/keyrings/jenkins-keyring.asc]" \ https://pkg.jenkins.io/debian-stable binary/ | sudo tee \ /etc/apt/sources.list.d/jenkins.list > /dev/null sudo apt-get update sudo apt-get install jenkins -y
Se puede ejecutar uno por uno o crear un script.sh y ejecutarlo.
También instalamos en este servidor, Trivy.
sudo apt-get install wget apt-transport-https gnupg lsb-release wget -qO - https://aquasecurity.github.io/trivy-repo/deb/public.key | sudo apt-key add - echo deb https://aquasecurity.github.io/trivy-repo/deb $(lsb_release -sc) main | sudo tee -a /etc/apt/sources.list.d/trivy.list sudo apt-get update sudo apt-get install trivy -y
Como vamos a utiliza Docker mas adelante, instalemos Docker también en esta misma maquina.
Para eso usamos el comando:
sudo apt install docker.io -y
Con respecto a Docker, debemos tener en cuenta que solo ejecuta comandos como usuario root, por lo que si otro usuario quiere ejecutar comandos Docker, debe tener permisos o usar sudo. Para evitar esto podemos agresar el usuario actual al grupo docker o ejecutar un script que le da permisos a todos los usuarios de la maquina.
sudo chmod 666 /var/run/docker.sock
Continuamos. Copiamos la ip publica del servidor Jenkins y con el puerto 8080 accedemos desde un navegador web.
ejemplo 98.87.13.136:8080
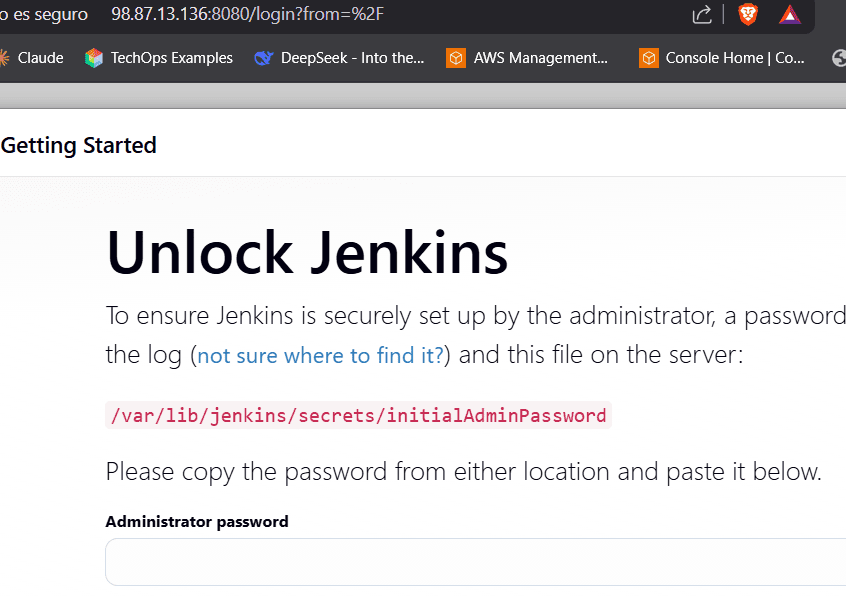
Ya tenemos acceso Jenkins
En la primera pantalla nos muestra donde esta el password para recuperarlo e ingresarlo.
Vamos a la terminal y le pedimos que nos muestre el contenido de el archivo, eso si, con permisos de root ya que se encuentra en la carpeta /var/.
sudo cat /var/lib/jenkins/secrets/initialAdminPassword

Copiamos, pegamos, continuamos.
Comienza la configuración de Jenkins.
En la pantalla que nos muestra, seleccionamos la opción que nos instala los plugins sugeridos. Y pasará a la siguiente pantalla.
Mientras eso se ejecuta, pasemos a la Instancia de Nexus.
Ya debería estar actualizada. Sino sudo apt update
Nexus lo vamos a instalar usando Docker por lo que vamos a crear un contenedor Docker. Asi que instalamos docker:sudo apt install docker.io -y
Como en esta maquina solo usaremos un par de comandos, no necesitamos darle permisos de root al usuario actual. Usemos sudo.
Entonces creamos la imagen Docker de Nexus en el puerto 8081 que es el que generalmente utiliza Nexus.sudo docker run -d -p 8081:8081 sonatype/nexus3
Ese comando ejecuta en segundo plano (-d) un contenedor de Nexus Repository Manager 3 usando la imagen oficial sonatype/nexus3, y expone el puerto 8081 del contenedor hacia el puerto 8081 de la máquina anfitriona, permitiendo acceder a la interfaz web de Nexus.
Nexus es una maquina que tarda unos minutos en configurarse internamente, por lo que no podremos acceder a el inmediatamente. Esperaremos algunos minutos.
Accedemos por el navegador web con la ip publica y el puerto 8081
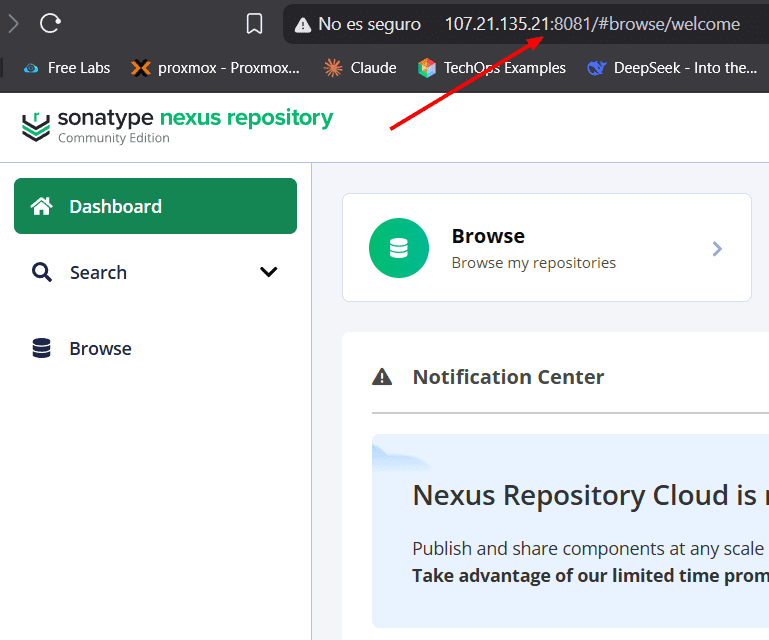
Listo Nexus.
Pasamos a la Instancia EC2 de SonarQube.
Actualizamos con sudo apt update si no lo hicimos anteriormente
Instalamos Dockersudo apt install docker.io -y
SonarQube utiliza por defecto el puerto 9000 así que se lo decimos al comando docker para instalar sonarQube y la imagen community que es la gratuita y de soporte a largo plazo.sudo docker run -d -p 9000:9000 sonarqube:lts-community
Y vamos al navegador web y accedemos con la ip publica y el puerto 9000
Tenemos hasta ahora, el servidor de Jenkins, el servidor de Nexus y el Servidor de SonarQube Activos.
Pasemos al paso 3: Configuracion de las herramientas.
Vamos al servidor con Jenkins.
Nos mostrará esta pantalla y debemos llenar los campos que nos pide:
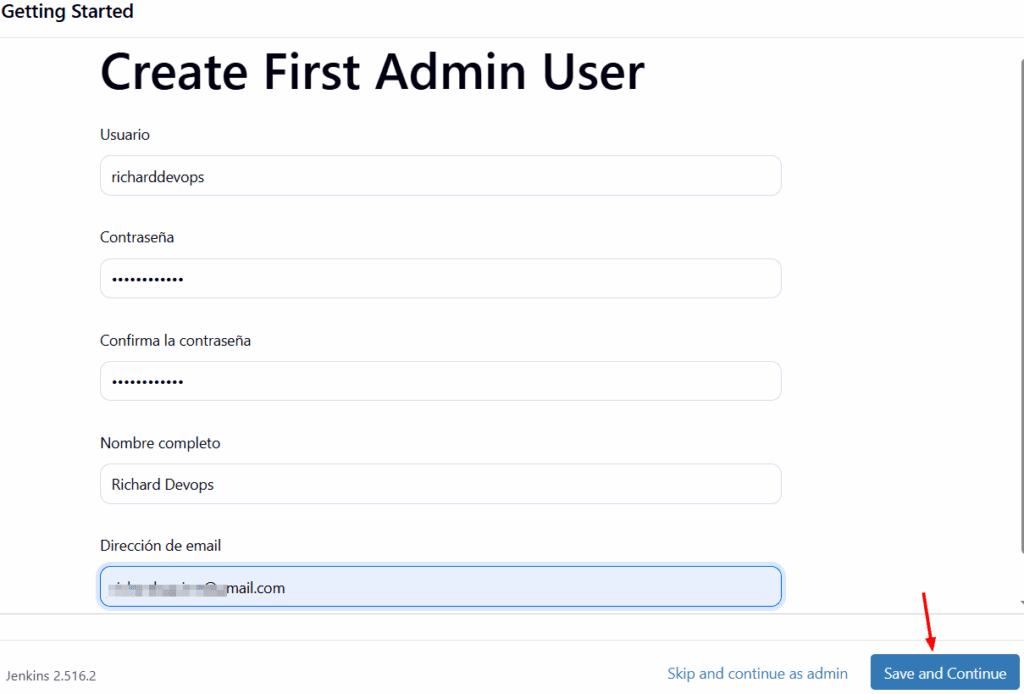

Continuamos
Continuamos al servidor de Nexus
Debemos loguearnos.
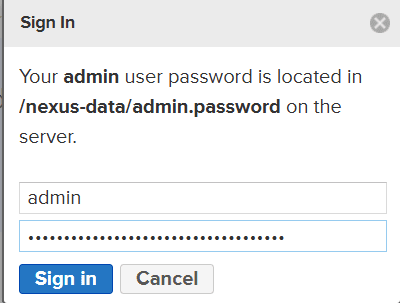
Nos pedirá un usuario admin y nos mostrará la ubicación de el password.
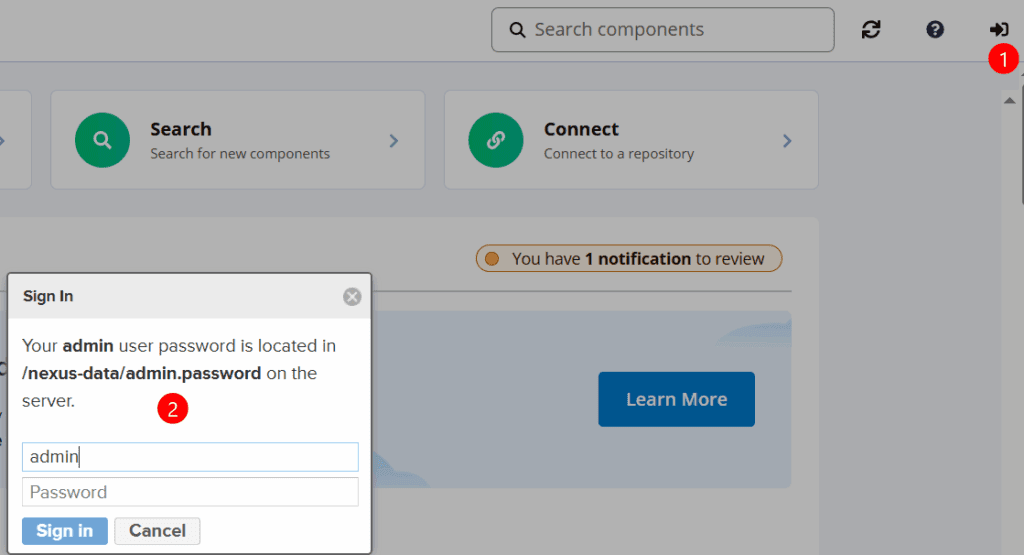
Como tenemos instalado Nexus en un contenedor de Docker, debemos ir al contenedor Docker para acceder a la ubicación donde se encuentra el password /nexus-data/admin.password.
Así que vamos a la terminal donde accedimos al servidor de nexus y ejecutamos el comando:sudo docker ps
nos muestra el id del contenedor de nexus.
Y ejecutamos seguidamente este comando:sudo docker exec -it d15e35190a05 /bin/bash

Y nos ha permitido ingresar al contenedor docker de Nexus
Accedemos a la carpeta sonatype-work/cd sonatype-work/nexus3/
y le pedimos que nos muestre el contenido de el archivo admin.passwordcat admin.password

Y nos muestra el password, que debemos copiar hasta antes de la palabra bash-5-1$
Ese password lo pegamos en el navegador web donde estamos configurando Nexus
Siguiente.
Le asignamos un nuevo password
Siguiente → Siguiente → Enable Anonimous Access. Siguiente → Finish.
Listo. Tenemos configurado Nexus.
Pasamos al navegador web donde tenemos SonarQube para iniciar la configuracion.
Pedirá usuario y password. Inicialmente son admin admin.
Nos pedirá el old password y el nuevo password. y Actualizamos
Finalizamos la configuracion inical de los 3 servidores, Jenkins, Nexus y sonarQube.
Bien Cuarto paso: Crear o escribir el Pipeline y Crear el Cluster EKS.
Antes de comenzar a crear nuestro pipeline debemos instalar algunos plugins en Jenkins, necesarios para trabajar la integración con Nexus, SonarQube, entre otras cosas.
Nos dirigimos a Jenkins, nos loguemos.
Vamos al botón administrar Jenkins
En Configuración de Sistema seleccionamos Plugins → Available pluins →
En la barra de búsqueda, buscamos sonar → seleccionamos SonarQube
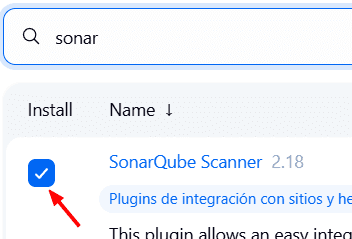
Ahora buscamos Config File Provider y lo seleccionamos tambien.
Buscamos Maven Integration y lo seleccionamos.
Buscamos Pipeline Maven Integration y lo seleccionamos.
Buscamos Kubernetes y lo seleccionamos.
Buscamos Kubernetes Credentials y lo seleccionamos.
Buscamos Kubernetes CLI y lo seleccionamos.
Buscamos Kubernetes Client API y lo seleccionamos. Algunos dependen de otros asi que se instalarán igualmente.
Buscamos Docker y Docker Pipeline y lo seleccionamos.
Por ultimo buscamos Pipeline: Stage View y lo seleccionamos.
Mejor te dejo una lista:
Jenkins Plugins:
- SonarQube Scanner
- Config File Provider
- Maven Integration
- Pipeline Maven Integration
- Kubernetes Credentials
- Kubernetes
- Kubernetes CLI 8.
- Kubernetes Client API
- Docker
- Docker Pipeline
- Pipeline: Stage View
Luego damos click en Install
Esta instalación tomará un tiempo.
Mientras tanto podemos ir a SonarQube y crear un token y usaremos mas adelante.
Vamos al menú Administration → Security → Users
Damos click aquí
Volvemos a Jenkins.
Vamos ahora a configurar los plugins que instalamos.
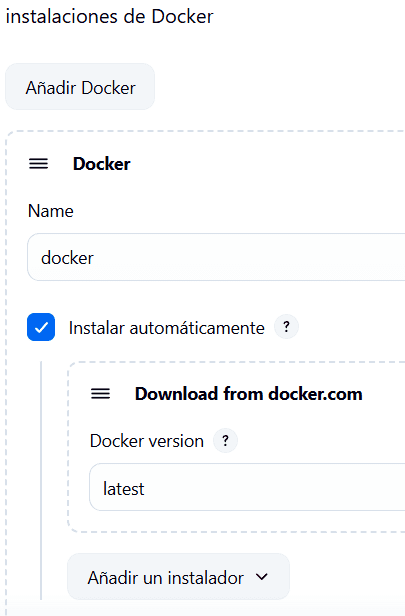
Damos click en Administrar Jenkins → Tools. Veremos varias secciones. Buscamos la sección instalaciones de Docker o Docker installations.
Add Docker → le damos un nombre: docker y marcamos instalar automaticamente.
Seguidamente en el menú Add Installer seleccionamos Download from Docker.com → latest
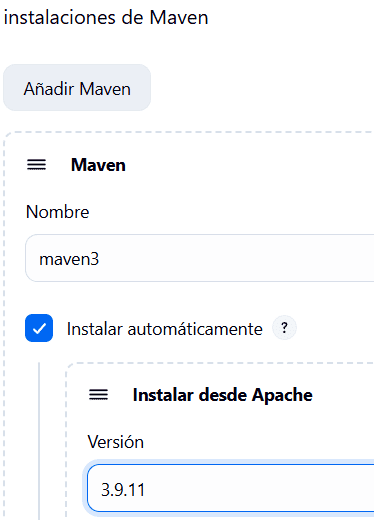
Hacemos algo parecido con Maven
Y algo parecido con SonarQube
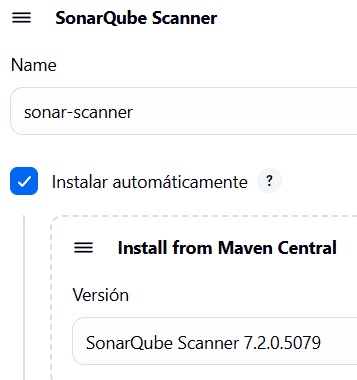
En caso de requerir otra versión de Java, podemos instalarla en esta parte. Jenkins permite manejar varias versiones de Java con el Elipse Temurin Installer.
Hacemos click en Aplicar – Guardar (Apply → Save).
Ahora si vamos a crear nuestro Pipeline
Seguimos en Jenkins → Vamos al Dashboard → new Item
Le damos un nombre: full-stack-bloggin-app y seleccionamos Pipeline
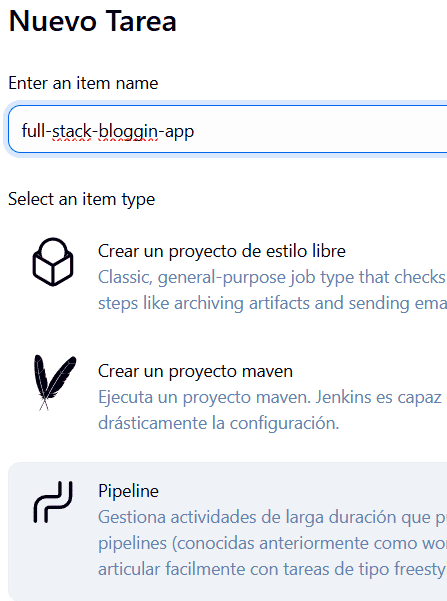
Y le damos clic en OK
En la siguiente pantalla marcamos las opciones
Desechar ejecuciones antiguas y le decimos que el Número máximo de ejecuciones para guardar será 2
Bajamos hasta la parte del Pipeline y en el menú de ejemplo, seleccionamos Hello Word. Esto para que nos muestre algunas líneas de código que modificaremos seguidamente.
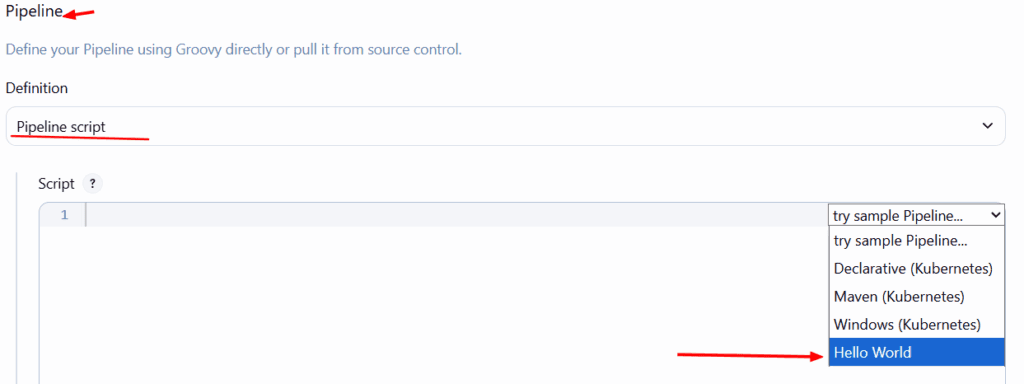
Algo que debemos tomar en cuenta es que vamos a utilizar varias herramientas que deben definirse manualmente en el script. Por ejemplo Maven, lo definimos en la parte de Tools de Jenkins con el nombre maven3. Ese es el nombre de la herramienta que debemos definir
tools { maven ‘maven3’ }
Cada stage debe estar definido en la parte de Stages en el Pipeline
El primer Stage que vamos a definir es Git Checkout y debemos descargar una copia del repositorio indicándoselo en el step. Podemos ayudarnos con el Pipeline Syntax para que nos cree el stage completo
En el Pipeline Syntax le indicamos que queremos hacer un step para git y nos pedirá el link de nuestro repositorio y la rama. Recordemos que nuestro repositorio es privado, así que debemos agregar una credencial, proporcionando el usuario y el token de Github.
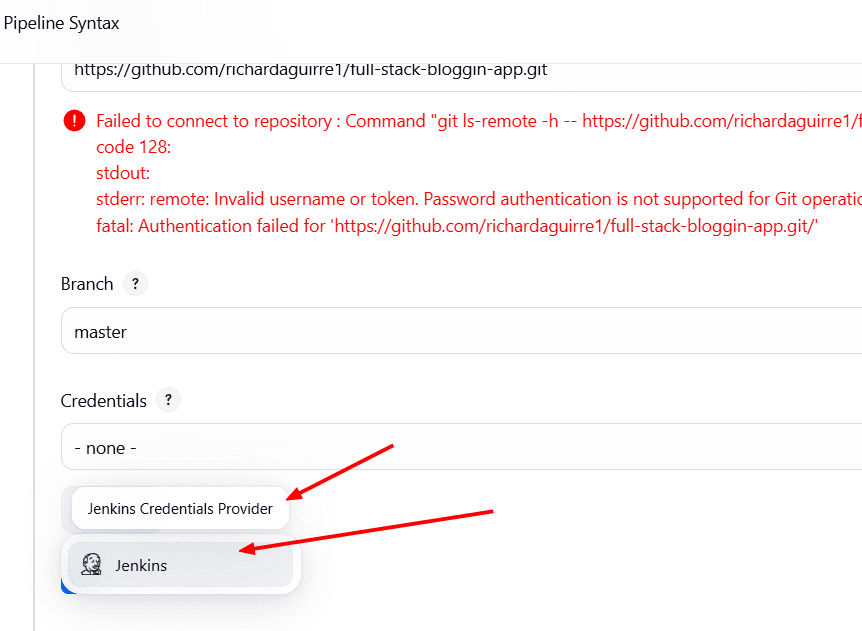
Quedándonos algo así:
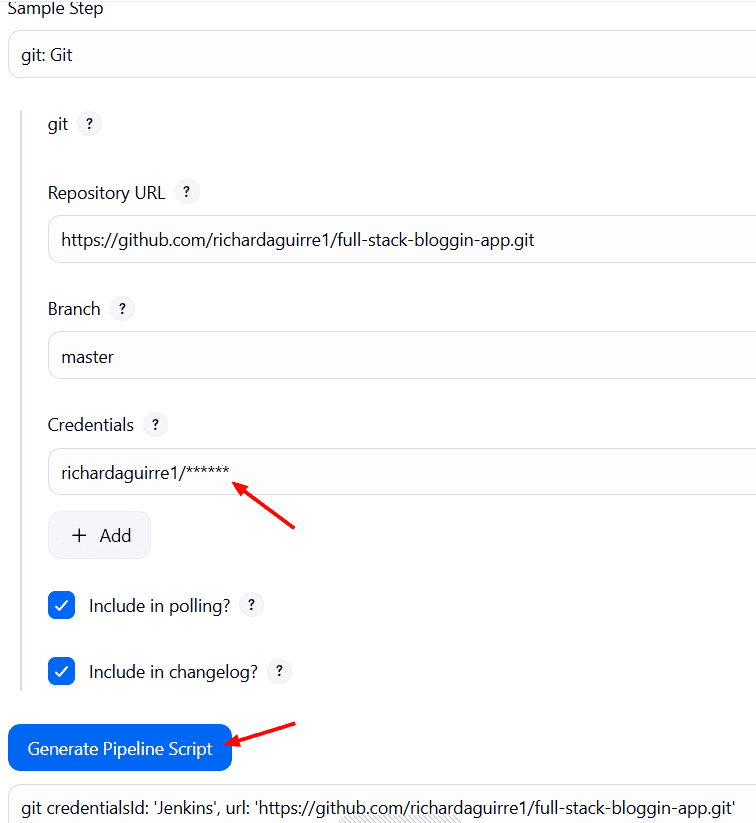
Copiamos el script generado y lo llevamos al step del Pipeline.
Entonces nuestro primer step nos quedaría así:
stage('Git Checkout') {
steps {
git credentialsId: 'Jenkins', url: 'https://github.com/richardaguirre1/full-stack-bloggin-app.git'
}
}
Pasamos a la etapa de Compilación y Pruebas
stage('Compile') {
steps {
sh "mvn compile"
}
}
Etapa de Test
stage('Test') {
steps {
sh "mvn test"
}
}
Etapa de escaneo de verificación con Trivy FS Scan
stage('Trivy') {
steps {
sh "trivy fs --format table -o fs.html ."
}
}
Etapa de análisis con SonarQube.
Para esto necesitamos 2 cosas. SonarQube server y SonarQube scanner.
Para configurar SonarQube Server debemos hacerlo en el panel de administración de Jenkins → Credentials. Para eso abrimos una nueva ventana en el navegador en Jenkins.
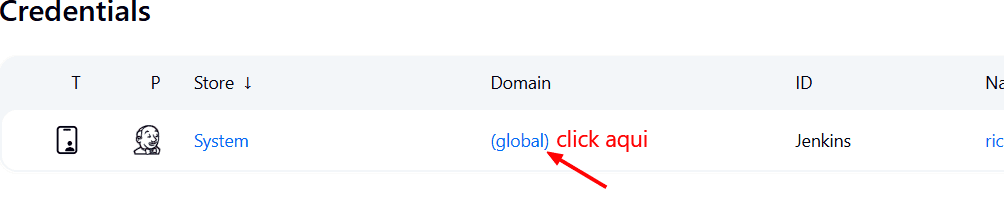
En la pantalla siguiente agregar credencial.
kind → secret text → secret: ingresamos el token de SonarQube que generamos algunos pasos atrás y que reservamos.
Y en ID colocamos: sonar-token.
Volvemos al panel de administración de Jenkins y esta ves vamos a System.
Buscamos SonarQube servers -Z Add SonarQube → name: sonar-server → URL del Servidor: http://3.88.5.107:9000/ y el server Authentication Token: el que creamos en el paso anterior.
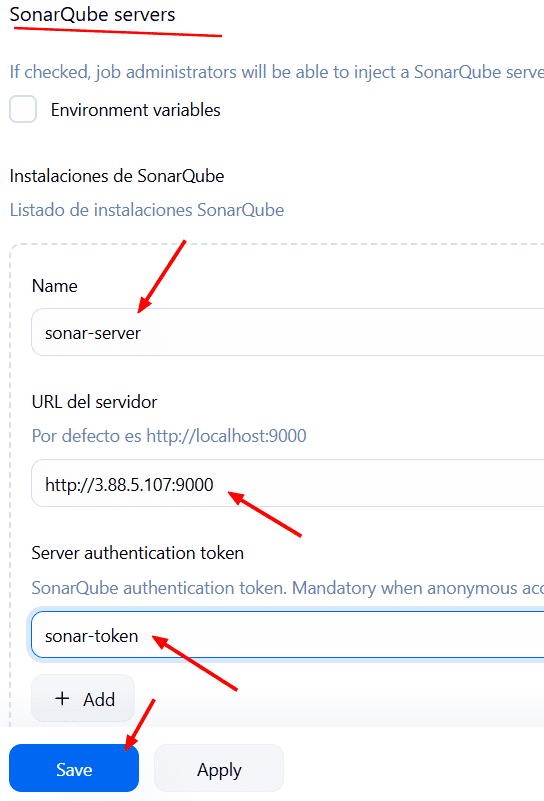
Aplicar y Guardar.
Ahora SonarQube esta configurado y listo para usar en Jenkins.
Volvemos al Pipeline.
Y configuramos la etapa de Scan que realizará el análisis y generará el informe y lo publicará en el servidor.
Para esto creamos un bloque de entorno (environment) al principio de el Pipeline, luego de el bloque tools.
environment {
SCANNER_HOME= tool 'sonar-scanner'
}
‘sonar-scanner’ es el nombre que le dimos a la herramienta cuando configuramos el plugin.
Volvemos a la etapa de SonarQube Analysis
Nos vamos a ayudar con el Pipeline Syntax
Como tenemos el servidor configurado en Jenkins con las credenciales, lo llamamos al pipeline con ” y contiene la URL. Luego mediante sh le indicamos los comandos para el análisis seguido de 3 (”’) es decir sh ”’ que significa que incluso si escribo varias líneas de código, se tomará como una sola.
stage('SonarQube Analysis') {
steps {
withSonarQubeEnv('sonar-server') {
sh '''$SCANNER_HOME/bin/sonar-scanner \
-Dsonar.projectKey=Blogging-app \
-Dsonar.projectName=Blogging-app \
-Dsonar.java.binaries=target'''
}
}
}
Pasamos a la Siguiente etapa Build lo que generará el artefacto y publicarlo.
stage('Build') {
steps {
sh "mvn package"
}
}
Seguidamente publicamos el artefacto en Nexus y debemos hacer que Jenkins se comunique al repositorio de Nexus y que la URL del repositorio de Nexus y las credenciales estén disponibles para Jenkins.
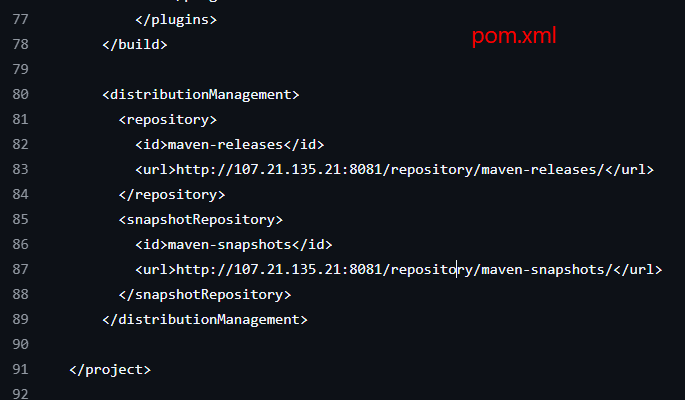
Para agregar la URL tenemos que ir al repositorio en Github y modificar el archivo pom.xml y agregar esta sección al final del código antes de la sección y guardamos. (commit changes)
<distributionManagement>
<repository>
<id>maven-releases</id>
<url>http://107.21.135.21:8081/repository/maven-releases/</url>
</repository>
<snapshotRepository>
<id>maven-snapshots</id>
<url>http://107.21.135.21:8081/repository/maven-snapshots/</url>
</snapshotRepository>
</distributionManagement>
Acá estamos agregando repositorios, un id, y una URL.
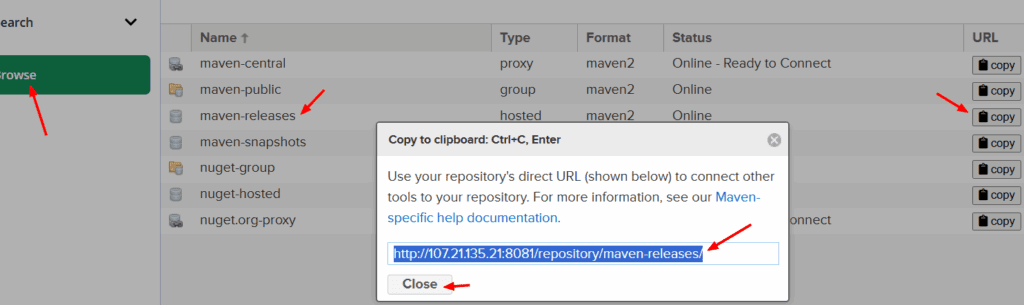
Donde podemos obtener la URL? Lo hacemos desde el servidor de Nexus → Browse → maven-releases → copy. y sustituimos en el código anterior la URL de el maven.release. Lo mismo para snapshotRepository
Quedando el pom.xml asi:
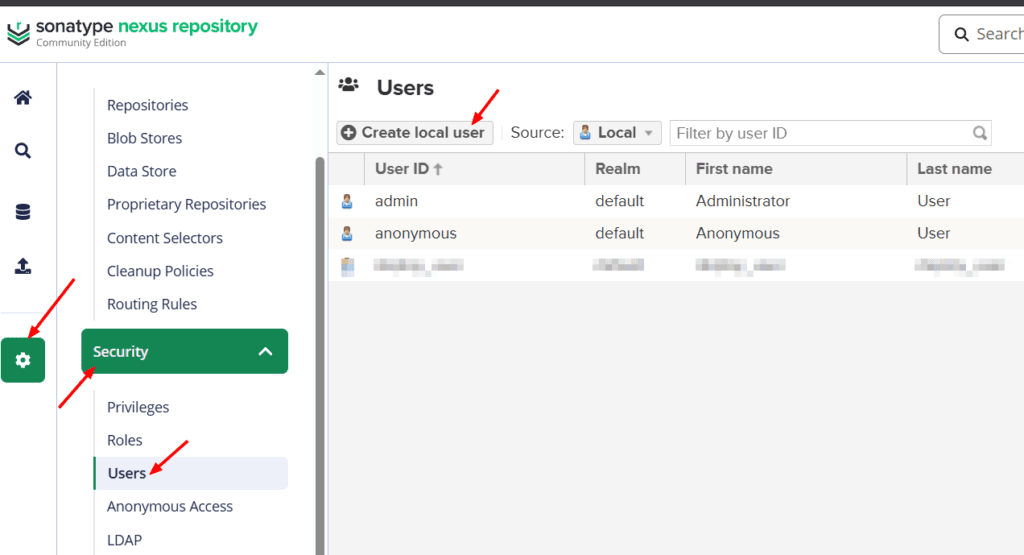
Vamos a Nexus para crear un usuario con permisos para publicar en el repositorio.
Si no estamos logueados debemos loguearnos.
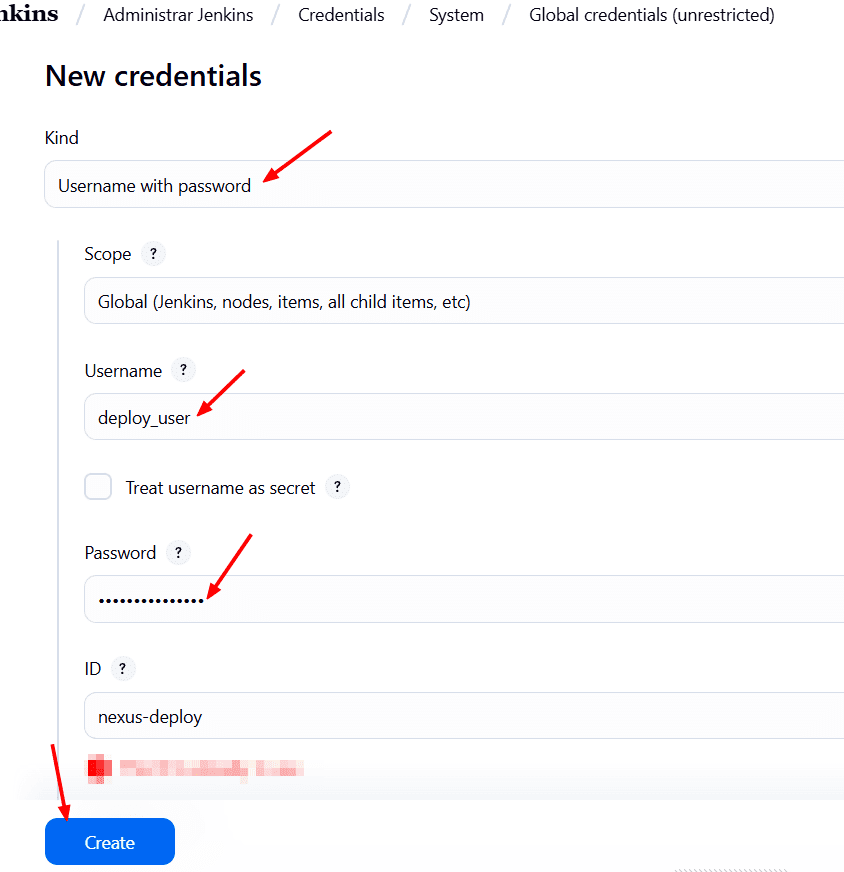
En Nexus → Settings → Security → Users → Create a local User.
En Id colocamos: deploy_user y en password: deploy_password o los valores que gustes.
El resto de valores los rellenas (Nombre, email etc.)
status: Active
Roles: agregar nx-admin.
Creamos el usuario.
Seguidamente vamos a Jenkins → Manage Jenkins → Credentials → Domain (global) →
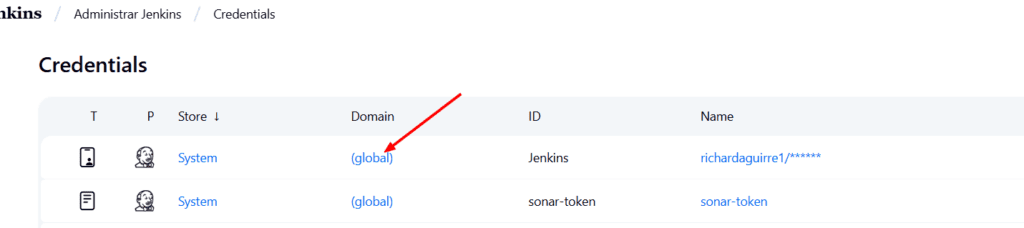
Click en Add Credentials → Kind: With User Name & Password → Indicamos el Username que creamos anteriormente en Nexus: deploy_user y el password, y como ID le colocamos: nexus-deploy → Create.
Ahora debemos agregar la credencial para Nexus.
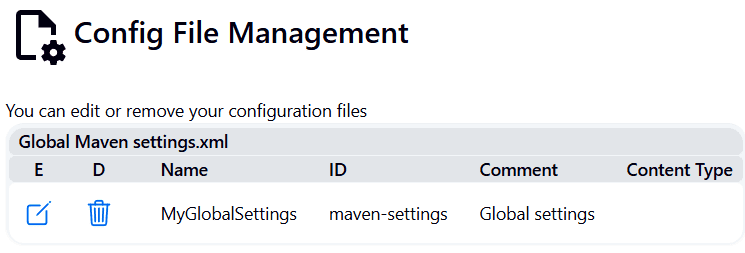
Para eso vamos a Jenkins → Manage Jenkins → Managed Files → Add New Config → Selecciona Global Maven Settings → ID: maven-settings → Click en Next.
En la siguiente pantalla, nos mostrará el contenido de el archivo settings dentro de el cual vamos a agregar las credenciales.
Nos desplazamos hasta la sección de servers y agregamos lo siguiente:
<server>
<id>maven-releases</id>
<username>${env.NEXUS_USER}</username>
<password>${env.NEXUS_PASS}</password>
</server>
<server>
<id>maven-snapshots</id>
<username>${env.NEXUS_USER}</username>
<password>${env.NEXUS_PASS}</password>
</server>
Vamos a la sección de mirrors y pegamos lo siguiente:
<mirror>
<id>nexus</id>
<url>http://107.21.135.21:8081/repository/maven-public/</url>
<mirrorOf>*</mirrorOf>
</mirror>
Vamos ala sección de profiles y pegamos lo siguiente:
<profile>
<id>nexus</id>
<repositories>
<repository>
<id>central</id>
<url>https://repo.maven.apache.org/maven2</url>
</repository>
</repositories>
</profile>
Vamos a la sección activeProfiles y pegamos lo siguiente:
<activeProfile>nexus</activeProfile>
Y guardamos.
Creamos el step de publicación de el Artefacto y Deploy con Maven
stage('Publish Artifacts') {
steps {
withMaven(globalMavenSettingsConfig: 'maven-settings', maven: 'maven3', traceability: true) {
sh "mvn deploy"
}
}
}
Hasta ahora este debe ser nuestro Pipeline:
pipeline {
agent any
tools {
maven 'maven3'
}
environment {
SCANNER_HOME = tool 'sonar-scanner'
}
stages {
stage('Git Checkout') {
steps {
git credentialsId: 'Jenkins', url: 'https://github.com/richardaguirre1/full-stack-bloggin-app.git'
}
}
stage('Compile') {
steps {
sh "mvn compile"
}
}
stage('Test') {
steps {
sh "mvn test"
}
}
stage('Trivy') {
steps {
sh "trivy fs --format table -o fs.html ."
}
}
stage('SonarQube Analysis') {
steps {
withSonarQubeEnv('sonar-server') {
sh '''$SCANNER_HOME/bin/sonar-scanner \
-Dsonar.projectKey=Blogging-app \
-Dsonar.projectName=Blogging-app \
-Dsonar.java.binaries=target'''
}
}
}
stage('Build') {
steps {
sh "mvn package"
}
}
stage('Publish Artifacts') {
steps {
withCredentials([usernamePassword(credentialsId: 'nexus-deploy', usernameVariable: 'NEXUS_USER', passwordVariable: 'NEXUS_PASS')]) {
withMaven(globalMavenSettingsConfig: 'maven-settings', maven: 'maven3') {
sh "mvn deploy"
}
}
}
}
}
}
Pasemos a Probar el Pipeline.
Aplicamos y Guardamos.
Buscamos Contruir Ahora y le damos click.
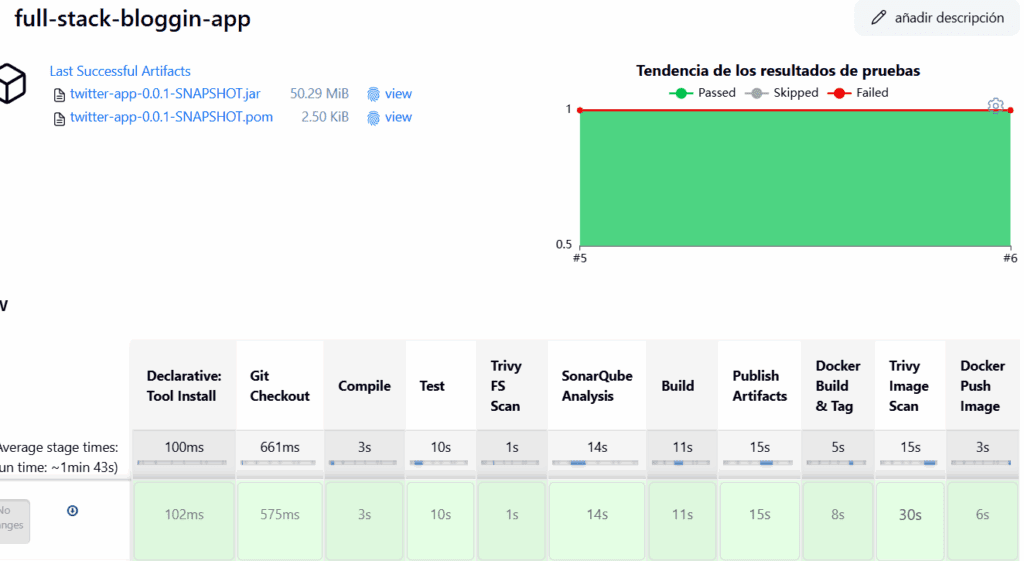
Y comienza el Pipeline.
Veremos como se van ejecutando cada una de las etapas que hemos creado.
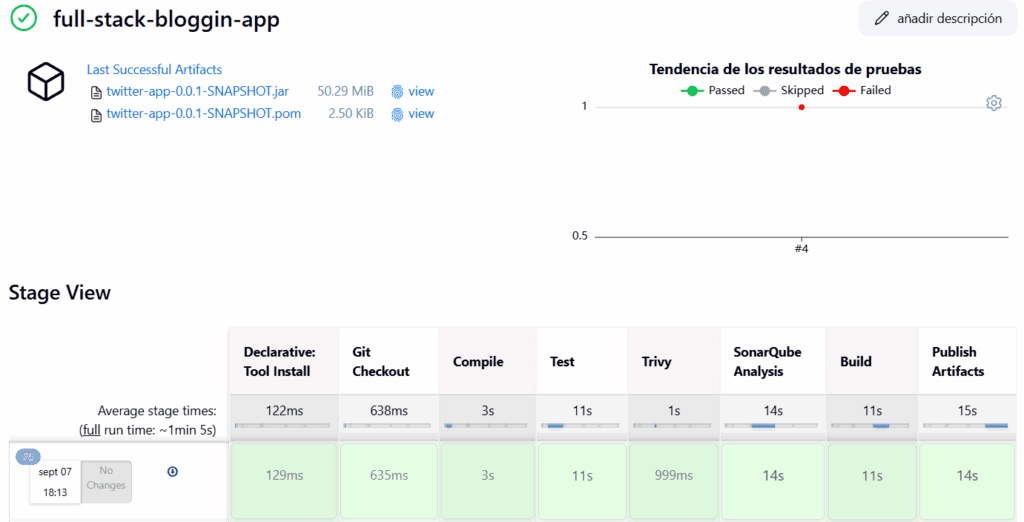
Vamos a Nexus y revisamos que este nuestro artefacto.
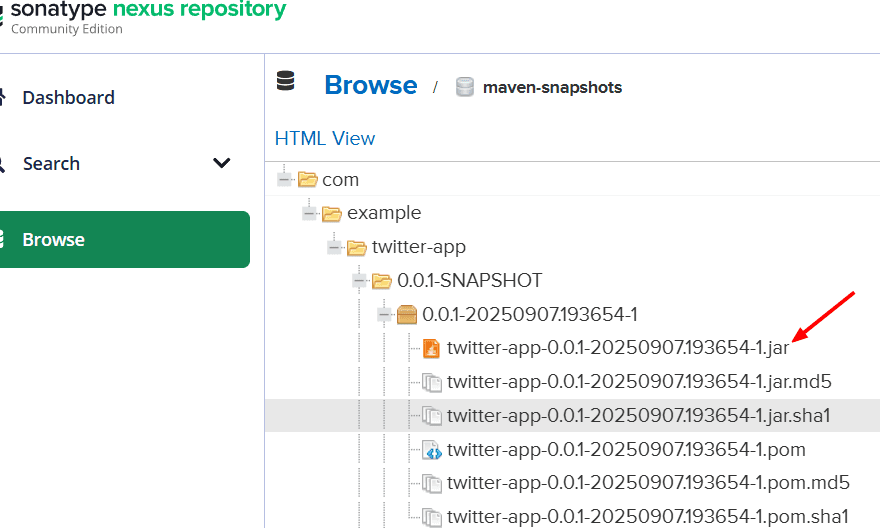
En Nexus debemos habilitar la opción Allow Redeploy para que un mismo artefacto pueda publicarse varias veces; para ello iniciamos sesión, vamos a Settings → Repositories, seleccionamos el repositorio (por ejemplo, maven-snapshots), cambiamos la Deployment Policy a Allow Redeploy y guardamos, de lo contrario en futuras ejecuciones del pipeline Maven devolverá un error al intentar desplegar un artefacto ya existente.
Nota: Allow Redeploy debe activarse en repositorios de tipo snapshot, pero no es recomendable en releases, porque contradice la filosofía de versionado inmutable.
Hasta ahora los casos de prueba se están ejecutando bien y tenemos los artefactos listos.
Pasemos a crear la Imagen Docker y enviarla al repositorio de Docker.
Vamos a Docker Hub y creamos un nuevo repositorio.
Copiamos el nombre del repositorio y lo reservamos
Vamos al Pipeline en Jenkins y creamos un stage. Podemos ayudarnos con Pipeline Sytax
→ withDockerRegistry
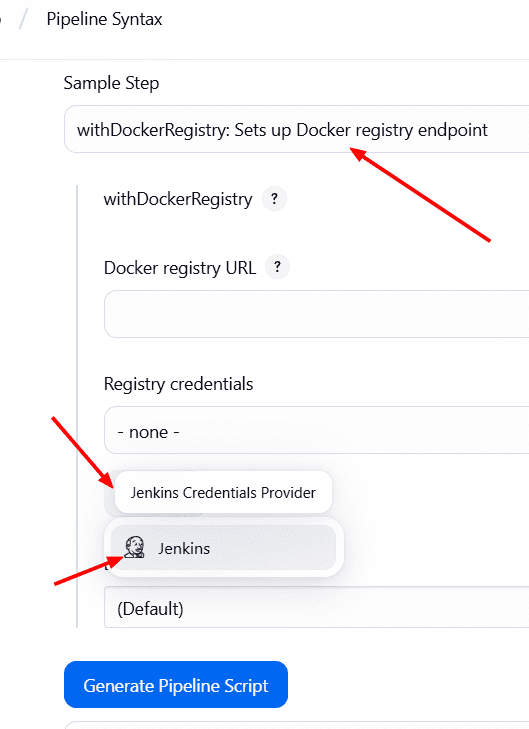
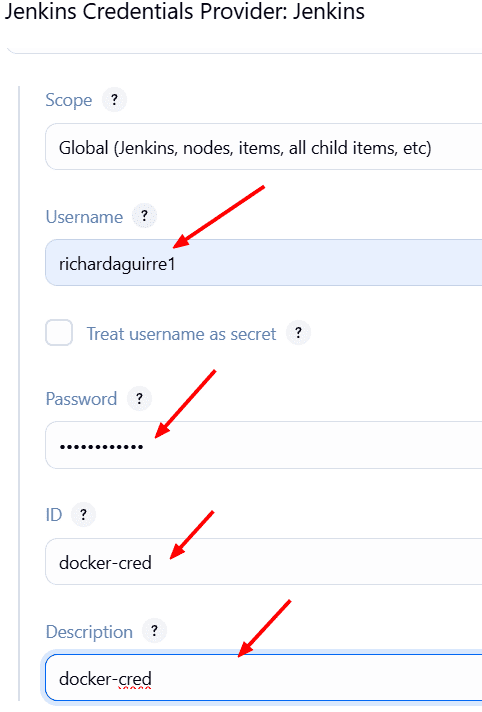
Configuramos las credenciales → Username and Password: e ingresamos las credenciales de nuestro Docker Hub. con el id: docker-cred y Guardamos.
Nos lleva de vuelta a Pipeline Syntax y seleccionamos la credencial que acabamos de crear y en Docker installation seleccionamos docker.
Generamos el script.
Nos quedaria asi:
withDockerRegistry(credentialsId: 'docker-cred', toolName: 'docker') {
// some block
}
Esto lo copiamos, volvemos al Pipeline y lo pegamos en el step de Docker quedando asi:
stage('Docker Build & Tag') {
steps {
script{
withDockerRegistry(credentialsId: 'docker-cred', toolName: 'docker') {
sh "docker build -t richardaguirrecloud/bloggingapp:latest . "
}
}
}
}
Ahora debemos escanear la imagen de Docker en busca de vulnerabilidades antes de enviarla al repositorio, y eso lo hacemos con Trivy.
stage('Trivy Image Scan') {
steps {
sh "trivy image --format table -o image.html richardaguirrecloud/bloggingapp:latest"
}
}
Y una vez escaneado pasamos a publicarlo
stage('Docker Push Image') {
steps {
script{
withDockerRegistry(credentialsId: 'docker-cred', toolName: 'docker') {
sh "docker push richardaguirrecloud/bloggingapp:latest"
}
}
}
}
Ejecutemos el Pipeline para ver como se comporta.
Vamos a Docker Hub y revisamos que este la imagen
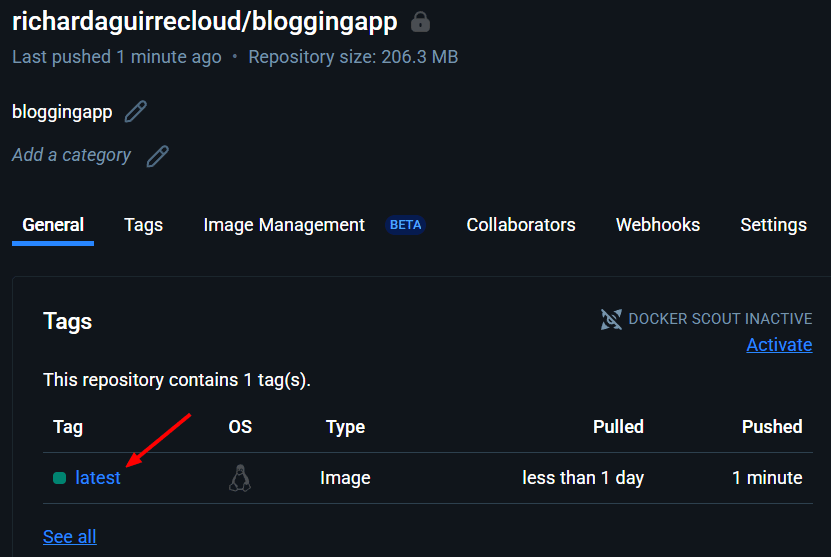
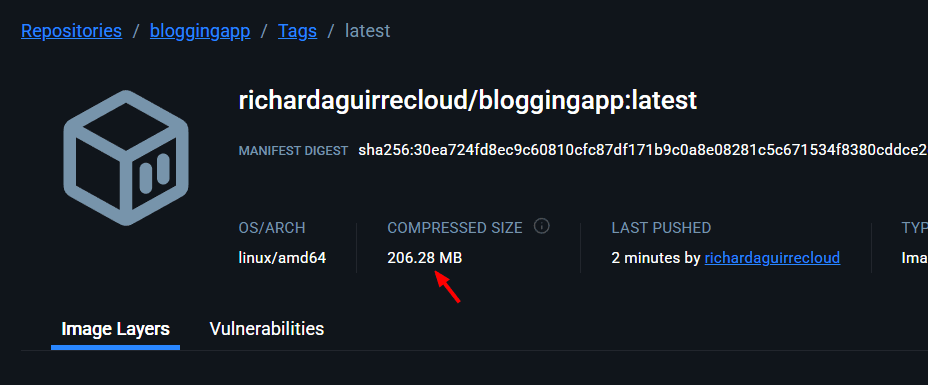
Perfecto. Sigamos.
Vamos a escribir los comandos para la implementación en el cluster de Kubernetes en EKS
Para esto vamos a utilizar Terraform.
Si no tenemos terraform instalado debemos crear una nueva instancia e instalar terraform.
Si tenemos ya instalado y configurado terraform en una maquina local o en una instancia EC2 podemos iniciar terraform. Los archivos .tf los tengo en el repositorio.
Creamos otra instancia EC2 en AWS.
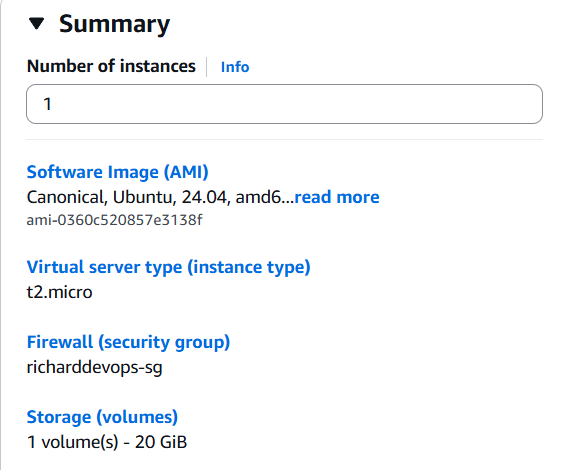
Nos conectamos via ssh y actualizamos.
sudo apt update
Instalamos la CLI de AWS.
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" sudo apt install unzip unzip awscliv2.zip sudo ./aws/install
Ejecutamosaws configure
Indicamos el AWS Access Key ID, el Secret Access Key y la región donde vamos a desplegar el cluster EKS.
Si no tenemos las credenciales, creamos una en AWS. Considera crear un usuario aparte, solo con los permisos necesarios.

Instalamos terraformsudo snap install terraform --classic
Una vez instalado Terraform, creamos una carpeta para agregar los archivo de terraform.mkdir terraformcd terraform
Creamos 3 archivos
sudo touch main.tf output.tf variables.tf
Editamos el archivo main.tf y le agregamos el código como sudo:
provider "aws" {
region = "us-east-1"
}
resource "aws_vpc" "bloggingapp_vpc" {
cidr_block = "10.0.0.0/16"
tags = {
Name = "bloggingapp-vpc"
}
}
resource "aws_subnet" "bloggingapp_subnet" {
count = 2
vpc_id = aws_vpc.bloggingapp_vpc.id
cidr_block = cidrsubnet(aws_vpc.bloggingapp_vpc.cidr_block, 8, count.index)
availability_zone = element(["us-east-1a", "us-east-1b"], count.index)
map_public_ip_on_launch = true
tags = {
Name = "bloggingapp-subnet-${count.index}"
}
}
resource "aws_internet_gateway" "bloggingapp_igw" {
vpc_id = aws_vpc.bloggingapp_vpc.id
tags = {
Name = "bloggingapp-igw"
}
}
resource "aws_route_table" "bloggingapp_route_table" {
vpc_id = aws_vpc.bloggingapp_vpc.id
route {
cidr_block = "0.0.0.0/0"
gateway_id = aws_internet_gateway.bloggingapp_igw.id
}
tags = {
Name = "bloggingapp-route-table"
}
}
resource "aws_route_table_association" "a" {
count = 2
subnet_id = aws_subnet.bloggingapp_subnet[count.index].id
route_table_id = aws_route_table.bloggingapp_route_table.id
}
resource "aws_security_group" "bloggingapp_cluster_sg" {
vpc_id = aws_vpc.bloggingapp_vpc.id
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
Name = "bloggingapp-cluster-sg"
}
}
resource "aws_security_group" "bloggingapp_node_sg" {
vpc_id = aws_vpc.bloggingapp_vpc.id
ingress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
Name = "bloggingapp-node-sg"
}
}
resource "aws_eks_cluster" "bloggingapp" {
name = "bloggingapp-cluster"
role_arn = aws_iam_role.bloggingapp_cluster_role.arn
vpc_config {
subnet_ids = aws_subnet.bloggingapp_subnet[*].id
security_group_ids = [aws_security_group.bloggingapp_cluster_sg.id]
}
}
resource "aws_eks_node_group" "bloggingapp" {
cluster_name = aws_eks_cluster.bloggingapp.name
node_group_name = "bloggingapp-node-group"
node_role_arn = aws_iam_role.bloggingapp_node_group_role.arn
subnet_ids = aws_subnet.bloggingapp_subnet[*].id
scaling_config {
desired_size = 3
max_size = 3
min_size = 3
}
instance_types = ["t2.large"]
remote_access {
ec2_ssh_key = var.ssh_key_name
source_security_group_ids = [aws_security_group.bloggingapp_node_sg.id]
}
}
resource "aws_iam_role" "bloggingapp_cluster_role" {
name = "bloggingapp-cluster-role"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "eks.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "bloggingapp_cluster_role_policy" {
role = aws_iam_role.bloggingapp_cluster_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSClusterPolicy"
}
resource "aws_iam_role" "bloggingapp_node_group_role" {
name = "bloggingapp-node-group-role"
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
EOF
}
resource "aws_iam_role_policy_attachment" "bloggingapp_node_group_role_policy" {
role = aws_iam_role.bloggingapp_node_group_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy"
}
resource "aws_iam_role_policy_attachment" "bloggingapp_node_group_cni_policy" {
role = aws_iam_role.bloggingapp_node_group_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy"
}
resource "aws_iam_role_policy_attachment" "bloggingapp_node_group_registry_policy" {
role = aws_iam_role.bloggingapp_node_group_role.name
policy_arn = "arn:aws:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly"
}
Debemos reemplazar la region por la nuestra. En este caso estoy usando us-east-1.
este código Terraform crea toda la infraestructura básica en AWS para un clúster de Kubernetes con EKS: define una VPC con dos subnets públicas, un Internet Gateway y tabla de ruteo, grupos de seguridad, los roles IAM necesarios, y finalmente despliega un EKS Cluster con un Node Group de 3 instancias t2.large que pueden ser accedidas por SSH, quedando lista una infraestructura gestionada de Kubernetes para correr aplicaciones.
Considera utilizar una instancia optimizada para costo.
Editamos el archivo output.tf como sudo:
output "cluster_id" {
value = aws_eks_cluster.bloggingapp.id
}
output "node_group_id" {
value = aws_eks_node_group.bloggingapp.id
}
output "vpc_id" {
value = aws_vpc.bloggingapp_vpc.id
}
output "subnet_ids" {
value = aws_subnet.bloggingapp_subnet[*].id
}
Y editamos el archivo variables.tf que contendrá los valores que terraform utilizará para crear los recursos. Debemos tener el nombre del KeyPair que deberíamos tener creado en AWS. Si no lo tenemos, creamos uno y lo pasamos a este código sustituyendo el valor default
variable "ssh_key_name" {
description = "The name of the SSH key pair to use for instances"
type = string
default = "richardevops-tests-kp"
}
Ejecutamos los comandos
terraform init
terraform plan
Deberá anunciar que se van a crear 17 recursos.
Y si todo esta correcto:
terraform apply --auto-approve
Ahora terraform comenzará a desplegar nuestra infraestructura.
Esto tomará cerca de 10 minutos.
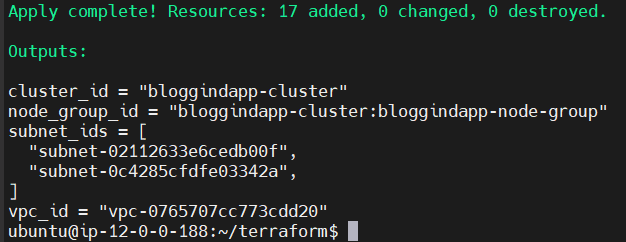
Una vez creado el cluster, lo verificamos en AWS
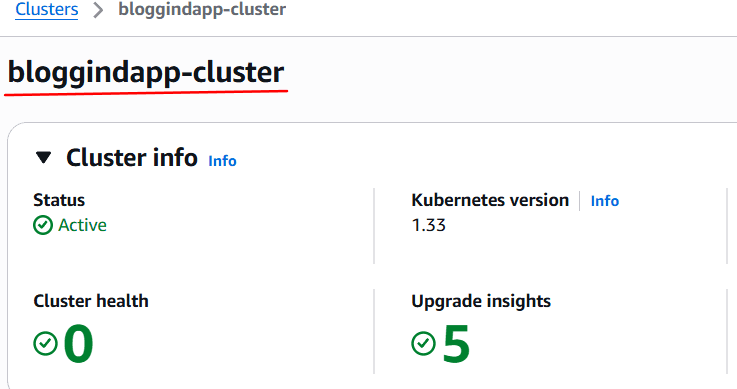
Volvemos a la instancia donde instalamos terraform.
Hasta ahora el cluster esta creado pero aun no nos hemos conectado a el.
Debemos conectarnos al cluster.
Instalamos ahora kubectl
curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.19.6/2021-01-05/bin/linux/amd64/kubectl chmod +x ./kubectl sudo mv ./kubectl /usr/local/bin kubectl version --short --client
Lo debemos instalar también en la instancia de Jenkins ya que lo vamos a usar mas adelante.
Volvemos a la instancia Terraform y nos conectamos con este comando sustituyendo el nombre de el cluster
aws eks --region us-east-1 update-kubeconfig --name bloggingapp-cluster

Y con esto ya estaríamos conectados al cluster.
Con el comando kubectl get nodes, nos mostrará los 3 nodos que creamos con terraform.
Siguiente paso, crear nuestra RBAC, control de acceso basado en reglas
Lo primero seria crear nuestra service Account y luego le daremos los permisos necesarios a esta cuenta de servicio para realizar la implementacion.
Vamos a la instancia donde instalamos terraform.
Volvemos una carpeta a trás.
Creamos un nuevo archivo con sudo de nombre svc.yml y le agregamos lo siguiente:
apiVersion: v1 kind: ServiceAccount metadata: name: bloggingapp namespace: webapps
Lo guardamos.
Ejecutamos el siguiente comando con el namespace webapps:
kubectl create ns webapps

Y creamos la cuenta de servicio o service account:
kubectl apply -f svc.yml
Hemos creado la cuenta de servicio dentro de el namespace webapps
Ahora vamos a crear un Rol dentro de webapps y la vamos a asignar a la cuenta de servicio bloggingapp.
Para eso creamos un archivo rol.yml y le agregamos lo siguiente:
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: bloggingapp-cluster-fullaccess rules: - apiGroups: ["*"] resources: ["*"] verbs: ["*"]
Nota: Esto da acceso total al clúster y no es recomendable en entornos productivos. NUNCA PERO NUNCA lo hagas, (es mejor restringir).
Y lo aplicamos:
kubectl apply -f rol.yml
Una vez creado el rol se lo asignamos al Service Account
Creamos el archivo bind.yml y le agregamos lo siguiente:
apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: app-rolebinding namespace: webapps subjects: - kind: ServiceAccount name: bloggingapp namespace: webapps roleRef: kind: Role name: app-role apiGroup: rbac.authorization.k8s.io
Y lo aplicamos
kubectl apply -f bind.yml
Ahora el ServiceAccount bloggingapp tiene permisos completos para realizar implementaciones, así como para actualizar y eliminar recursos en el clúster.
Por ultimo necesitamos crear un token para el service account.
Creamos un nuevo archivo blog-secret.yml y le agregamos:
apiVersion: v1
kind: Secret
type: kubernetes.io/service-account-token
metadata:
name: blog-secret
namespace: webapps
annotations:
kubernetes.io/service-account.name: bloggingapp
Y lo aplicamos asegurándonos de que tome el namespace webapps:
kubectl apply -f blog-secret.yml -n webapps
Por otra parte tenemos el Docker Registry como privado.
El deployment-service.yml contiene el manifiesto de Kubernetes para describir cómo se despliega tu aplicación y cómo se expone en la red.
Vamos a Github y generamos el deployment-service.yml sustituyendo el nombre del repositorio de Docker Registry por el tuyo:
apiVersion: apps/v1
kind: Deployment
metadata:
name: bloggingapp-deployment
spec:
selector:
matchLabels:
app: bloggingapp
replicas: 2
template:
metadata:
labels:
app: bloggingapp
spec:
containers:
- name: bloggingapp
image: richardaguirrecloud/bloggingapp:latest # Updated image to private DockerHub image
imagePullPolicy: Always
ports:
- containerPort: 8080
imagePullSecrets:
- name: regcred # Reference to the Docker registry secret
---
apiVersion: v1
kind: Service
metadata:
name: bloggingapp-ssvc
spec:
selector:
app: bloggingapp
ports:
- protocol: "TCP"
port: 80
targetPort: 8080
type: LoadBalancer
Entonces para que el deployment-service.yml pueda ser usado por Kubernetes, debemos proporcionarle el secret o las credenciales.
Si nos vamos al repositorio en Github podremos ver este archivo.
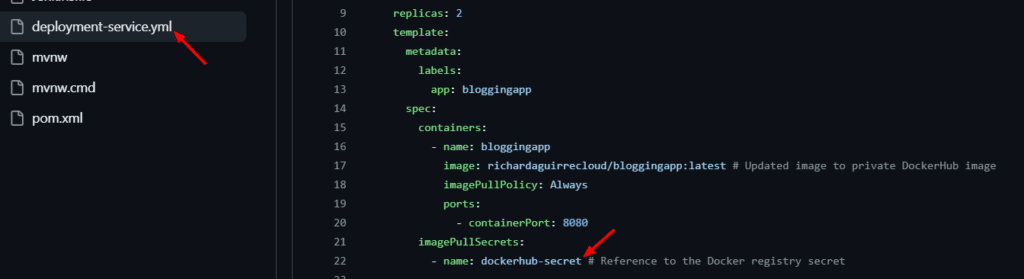
En este caso le coloqué al secret como nombre: dockerhub-secret
Vamos a Docker Hub generamos un token de acceso personal y lo reservamos
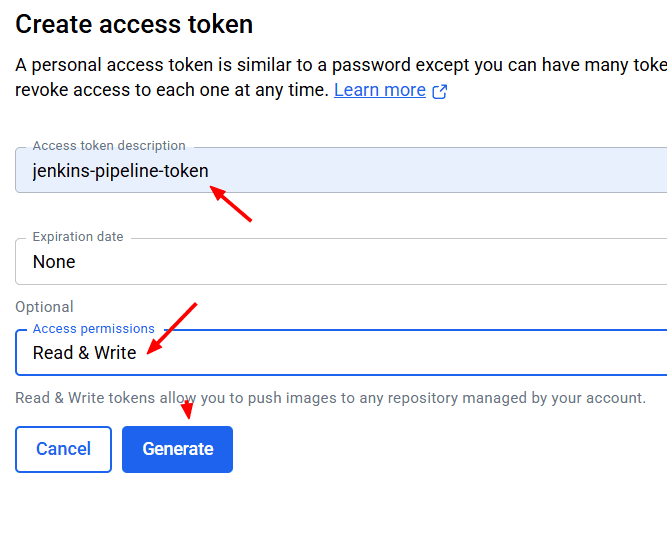
Ejecutamos estos comandos en la instancia donde tenemos instalado kubectl y sustituimos los valores como tu docker-username y el docker-password (recien generado),namespace webapps
kubectl create secret docker-registry dockerhub-secret \ --docker-server=https://index.docker.io/v1/ \ --docker-username=richardaguirrecloud \ --docker-password=dckr_pat_xxxxxx_xxxxx_xxxxxxxxxxxx \ --docker-email=dockeruser@richarddevops.site \ --namespace=webapps
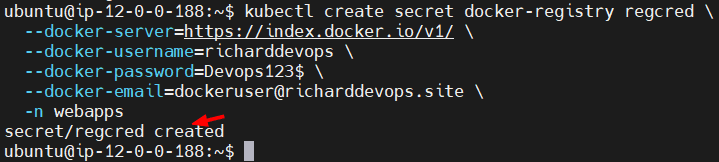
Hemos creado el secret para que la imagen se pueda extraer del Docker Registry.
Y creamos el Service Account en el namespace webapps
kubectl create serviceaccount bloggingapp -n webapps
Debemos crear otro secret que se usará para la autenticación de Jenkins con Kubernetes.
Si ejecutamos el comando:
kubectl get secrets -n webapps
Veremos que tenemos 2 secrets.

Uno es para la extracción de la imagen y el otro es el token de autenticación de el Service Account.
Le pedimos que nos muestre el secret de el service account
kubectl describe secret blog-secret -n webapps
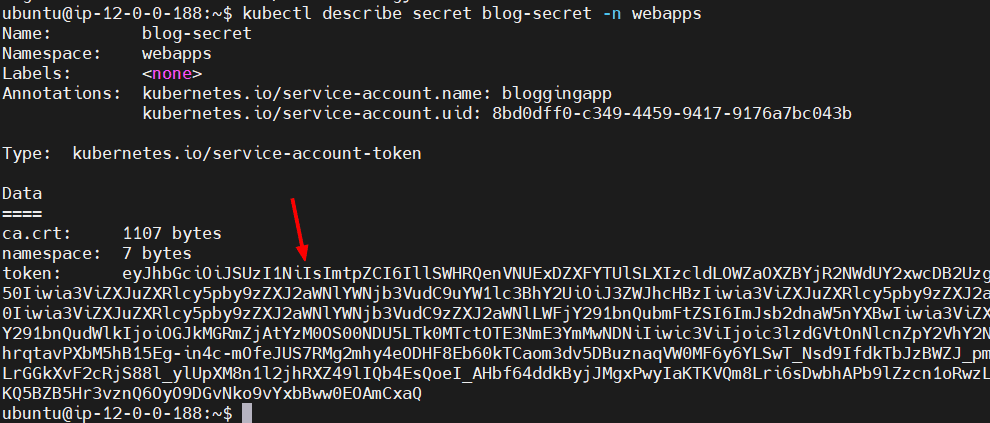
Copiamos todo el token y lo reservamos.
Volvamos a Jenkins y creamos una nueva credencial (Credentials)
Click en (global) → Add Credential → Secret Text → Pegamos el token que copiamos → y como ID: k8-cred → Create.
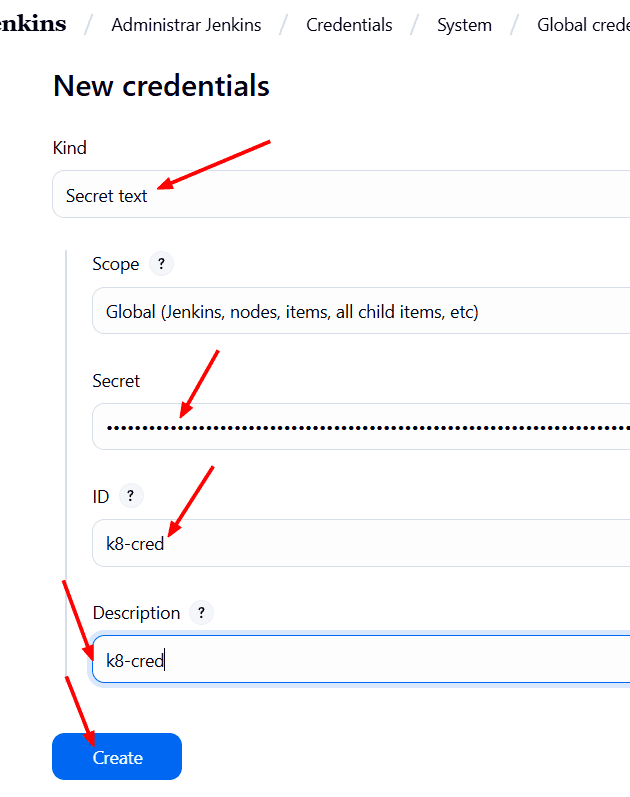
Listo.
Volvemos al Pipeline en Jenkins.
Bajamos al final de el Pipeline y agregamos un nuevo Stage para el Deploy de Kubernetes.
Podemos ayudarnos con el Pipeline Sytax. → withKubeConfig
Debemos proporcionar la credencial que acabamos de crear, el endpoint de Kubernetes (en AWS), el nombre de el cluster y el namespace.
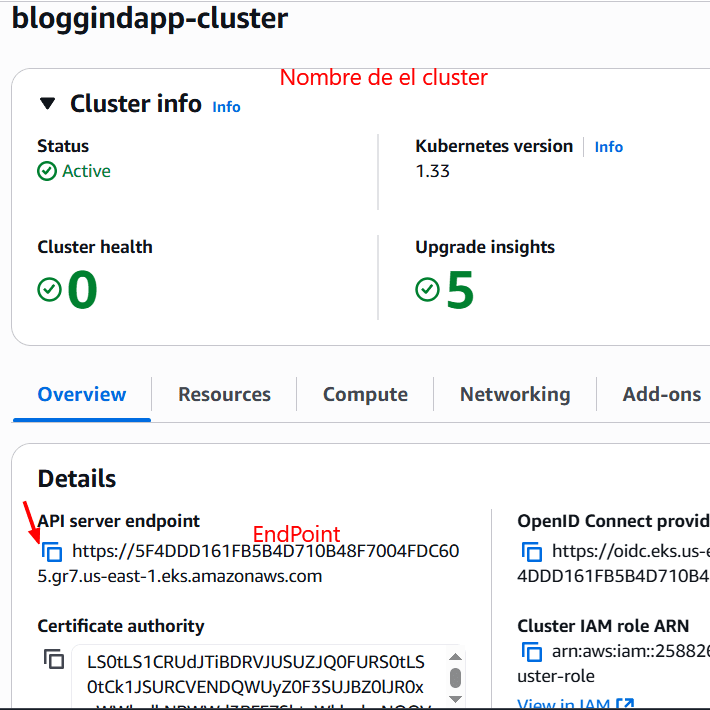
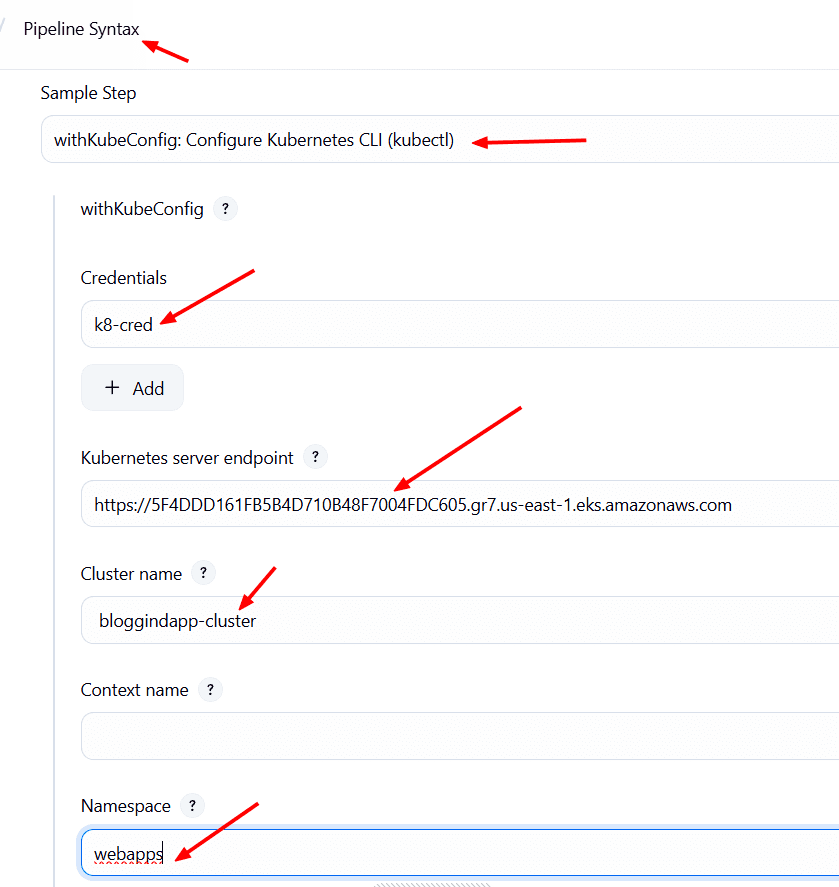
Y lo generamos.
Con esa guía podemos configurar el Stage para ejecutar el kubectl apply de el deployment-service.yml
Nos queda el stage así:
stage('K8-Deploy') {
steps {
withKubeConfig(caCertificate: '', clusterName: ' bloggingapp-cluster', contextName: '', credentialsId: 'k8-cred', namespace: 'webapps', restrictKubeConfigAccess: false, serverUrl: 'https://5F4DDD161FB5B4D710B48F7004FDC605.gr7.us-east-1.eks.amazonaws.com') {
sh "kubectl apply -f deployment-service.yml"
sleep 30
}
}
}
Nota: este archivo debe estar en el repositorio de GitHub clonado por Jenkins o en el workspace.
Creamos otro Stage muy parecido al anterior para la verificación de el deployment
stage('Verify Deployment') {
steps {
withKubeConfig(caCertificate: '', clusterName: ' bloggingapp-cluster', contextName: '', credentialsId: 'k8-cred', namespace: 'webapps', restrictKubeConfigAccess: false, serverUrl: 'https://5F4DDD161FB5B4D710B48F7004FDC605.gr7.us-east-1.eks.amazonaws.com') {
sh "kubectl get pods"
sh "kubectl get svc"
}
}
}
La ultima etapa de este Pipeline será la notificación por email. En caso de que el Pipeline se complete o falle, se notificará por email.
Este código se agrega a nivel de pipeline:
post {
always {
script {
def jobName = env.JOB_NAME
def buildNumber = env.BUILD_NUMBER
def pipelineStatus = currentBuild.result ?: 'UNKNOWN'
def bannerColor = pipelineStatus.toUpperCase() == 'SUCCESS' ? 'green' : 'red'
def body = """
<html>
<body>
<div style="border: 4px solid ${bannerColor}; padding: 10px;">
<h2>${jobName} - Build ${buildNumber}</h2>
<div style="background-color: ${bannerColor}; padding: 10px;">
<h3 style="color: white;">Pipeline Status: ${pipelineStatus.toUpperCase()}</h3>
</div>
<p>Check the <a href="${BUILD_URL}">console output</a>.</p>
</div></body>
</html>
"""
emailext (
subject: "${jobName} - Build ${buildNumber} - ${pipelineStatus.toUpperCase()}",
body: body,
to: 'richardaguirre@gmail.com',
from: 'richarddevops@example.com',
replyTo: 'suscribe@example.com',
mimeType: 'text/html'
)
}
}
}
Ahora, si queremos que las notificaciones por email (Gmail en este caso) realmente funcionen, como debería, debemos configurarlas.
Vamos a Manage Jenkins → System.
Buscamos Extended E-Mail Notification y Notificación por correo electrónico estan casi al final.
Debemos tener un password de aplicaciones para el correo electrónico que usará Jenkins para enviar las Notificaciones.
Para eso vamos a el siguiente link
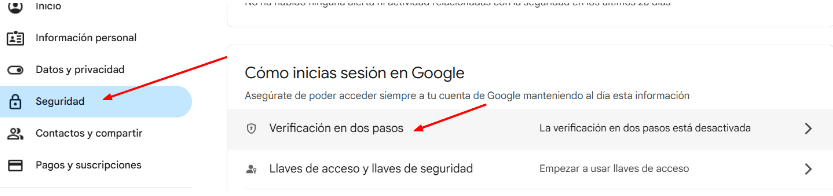
https://myaccount.google.com/apppasswords
Iniciamos sesión en nuestra cuenta de correo electrónico de google
Si no tenemos activo el 2FA no tendrás la opción.
O también se podría Usar un servidor SMTP alternativo (ejemplo: el SMTP de tu empresa, Mailtrap, Amazon SES, SendGrid). Usar un relay SMTP interno (si tienes uno en tu red/infraestructura). Configurar credenciales OAuth2 en Jenkins para Gmail, pero es bastante más complejo.
Nota: Es obligatorio activar la verificación en dos pasos (2FA) para generar app passwords en Google. Si no, Gmail no mostrará la opción.
Y creamos el password:
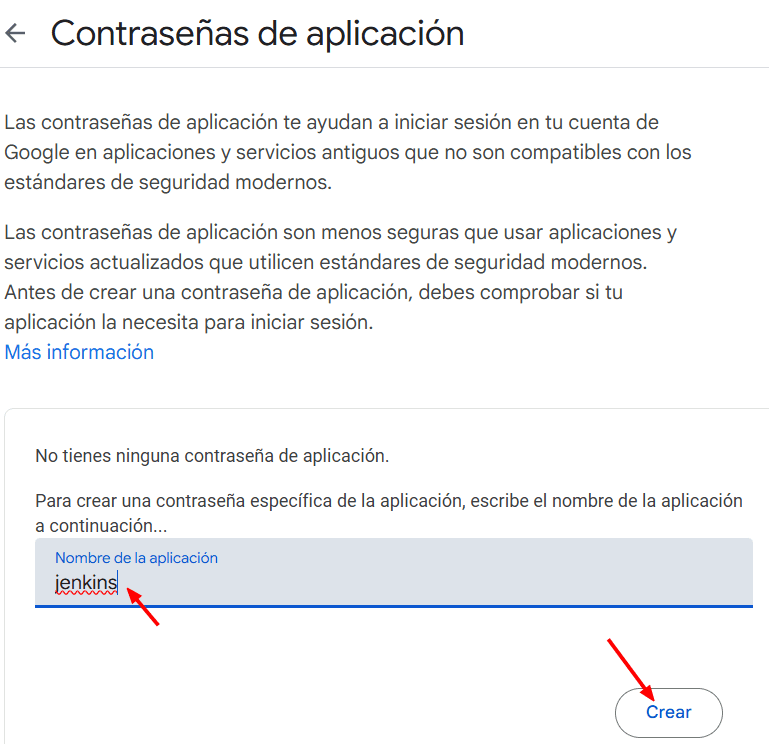
Copiamos el password

Volvemos a Jenkins → System → Notificación por correo electrónico
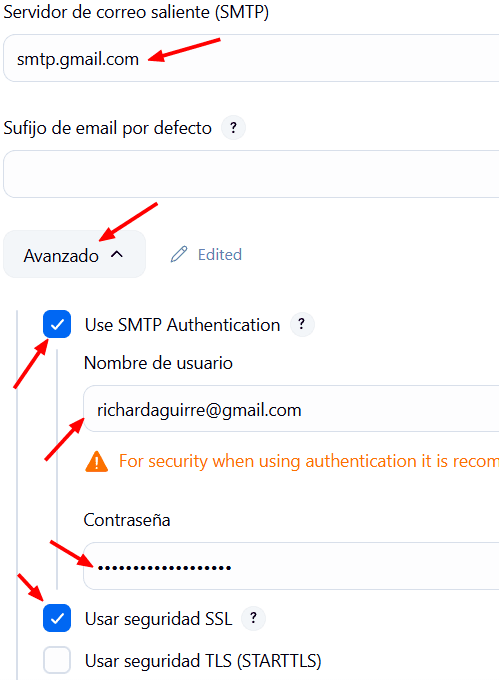
En SMTP colocamos smtp.gmail.com
Damos click en Avanzado. → Use SMTP Autentication.
Le proporcionamos el nombre del correo y la contraseña que acabamos de generar.
Y seleccionamos Seguridad SSL
y por último el puerto 465. (Este puerto debe estar permitido en el Security Group que creamos en AWS). Si no, debemos habilitarlo (Permitir SMTP desde cualquier origen).
Podemos hacer una prueba con Test Notification

Y en tu email debe llegar un correo nuevo indicando que se envió correctamente la notificación
Para Extended E-mail Notification, hacemos algo parecido.
smtp.gmail.com
puerto: 465
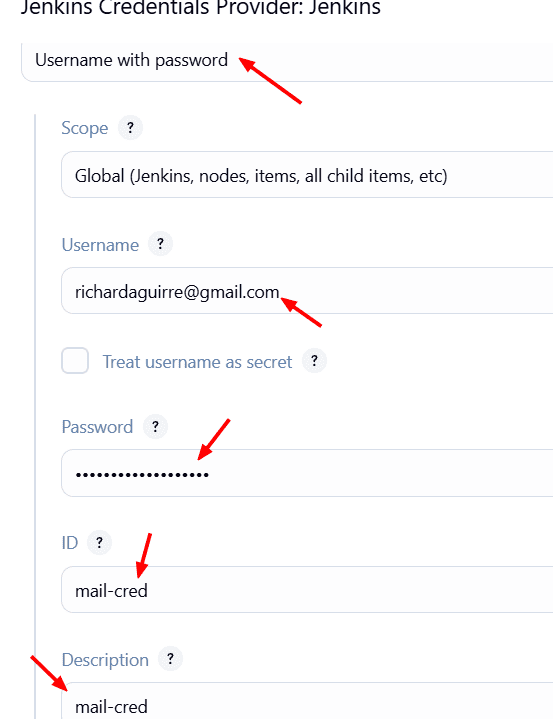
Creamos una nueva credencial en Jenkins..
A la credencial de indicamos que es Username with Password.
Le indicamos en username: el correo, y en password: la contraseña que generamos, un id: mail-cred, una descripcion: mail-cred y la agregamos.
Seleccionamos la credencial que acabamos de crear.
Seleccionamos Use SSL.
Y finalmente aplicamos la configuración.
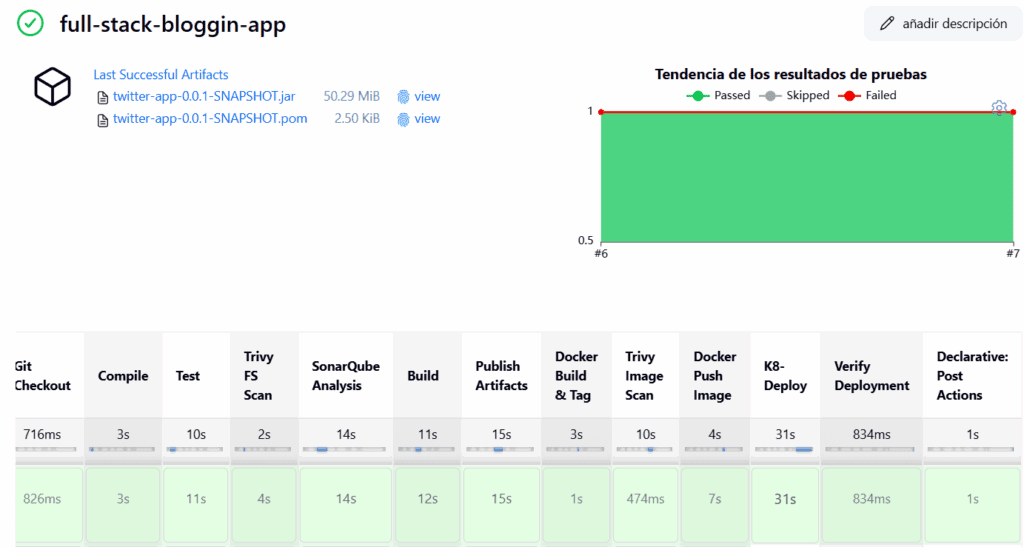
Ahora si probemos el Pipeline.
Si todo ha ido bien, veras un hermoso Pipeline y habrás recibido un email de notificación.
Luego de un par de minutos, podremos acceder a la URL del LoadBalancer y ver nuestra aplicacion en el navegador web.
Y podremos probarla.
Pasamos al aparte final: Monitoreo
Primeramente debemos tener una nueva Instancia EC2. t2.large al menos.
La creamos desde AWS Y nos conectamos por ssh.
La actualizamos
sudo apt update
Instalamos Grafana para linux Ubuntu:
sudo apt-get install -y adduser libfontconfig1 musl wget [https://dl.grafana.com/grafana-enterprise/release/12.1.1/grafana-enterprise_12.1.1_16903967602_linux_amd64.deb](https://dl.grafana.com/grafana-enterprise/release/12.1.1/grafana-enterprise_12.1.1_16903967602_linux_amd64.deb) sudo dpkg -i grafana-enterprise_12.1.1_16903967602_linux_amd64.deb
Iniciamos Grafana Server
sudo /bin/systemctl start grafana-server
Tendremos el servidor Grafana disponible desde la ip del servidor en el puerto 3000
El usuario y password predeterminado es admin admin.
Iniciamos sesión.
Le asignamos un nuevo password
Vamos nuevamente a la instancia Monitor.
Descargamos Prometheus para linux
wget https://github.com/prometheus/prometheus/releases/download/v3.6.0-rc.0/prometheus-3.6.0-rc.0.linux-amd64.tar.gz
Lo extraemos
tar -xvf prometheus-3.6.0-rc.0.linux-amd64.tar.gz
Nos deja una carpeta prometheus-3.6.0-rc.0.linux-amd64
Podemos remover el .tar.gs
Podemos renombrar a solo Prometheus
mv prometheus-3.6.0-rc.0.linux-amd64/ prometheus
Descargamos el blackbox_exporter para linux
wget https://github.com/prometheus/blackbox_exporter/releases/download/v0.27.0/blackbox_exporter-0.27.0.linux-amd64.tar.gz
Extraemos:
tar -xvf blackbox_exporter-0.27.0.linux-amd64.tar.gz
Renombramos:
mv blackbox_exporter-0.27.0.linux-amd64/ blackbox
accedemos a la carpeta Prometheus
cd prometheus
ejecutamos
./prometheus
se ejecuta en el puerto 9090
Podremos acceder por la ip publica del servidor con el puerto 9090 desde el navegador web.
Tenemos acceso a Prometheus
ippublica:9090
Vamos a la carpeta de blackbox
cd .. cd blackbox
Ejecutamos
./blackbox_exporter &
le agregamos un & para que se ejecute en segundo plano
Y esto se ejecutará en el puerto 9115
Probamos el una nueva ventana de el navegador
ippublica:9115
BlackBox se esta ejecutando.
Volvamos al terminal.
Vamos a la carpeta de Prometheus
editamos el archivo prometheus.yml
Pegamos el siguiente codigo despues de la linea – targets: [“localhost:9090”]
- job_name: 'blackbox'
metrics_path: /probe
params:
module: [http_2xx] # Look for a HTTP 200 response.
static_configs:
- targets:
- http://prometheus.io # Target to probe with http.
- http://example.com:8080 # Target to probe with http on port 8080.
relabel_configs:
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
- target_label: __address__
replacement: 127.0.0.1:9115
Este código lo podemos encontrar en el repositorio de Blackbox dentro de Prometheus
https://github.com/prometheus/blackbox_exporter
En – http://example.com:8080 reemplazamos el example por tu dominio.
Eliminamos las ultimas 3 líneas.
Guardamos.
Detenemos el proceso de prometheus.
pgrep prometheus
Nos muestra el id_de_proceso
kill id_de_proceso
E iniciamos prometheus nuevamente en segundo plano
./prometheus &
Si se produce un error, revisa el prometheus.yml o considera eliminar las líneas de código que están después de replacement: 127.0.0.1:9115
Vamos a la interfaz web de Prometheus y debe mostrarnos el status de el target
Vamos a la interfaz web de Grafana → Menu Connections → Data sources → Add Data Source → Prometheus.
Y en Connections le indicamos la URL de el servidor de Prometheus con el puerto 9090.
Bajamos → Save and Test.
Ahora creamos un Dashboard importándolo:
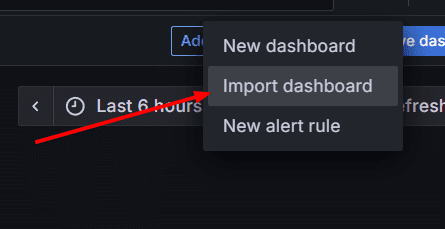
Debemos obtener el ID
Para eso nos vamos a este link:
https://grafana.com/grafana/dashboards/7587-prometheus-blackbox-exporter/
Y damos clic en el botón Copy Id to Clipboard
Volvemos a Grafana.
Pegamos el ID y le damos clic en Load
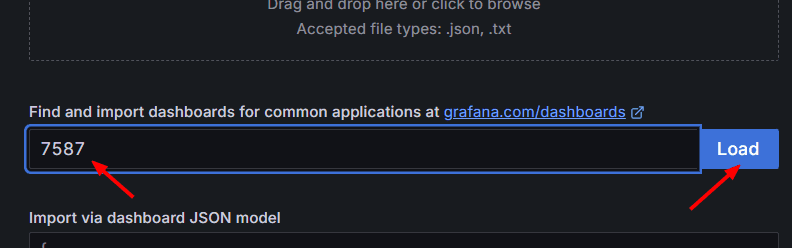
Seleccionamos el Data Source y clic en Import
Y tenemos monitoreo
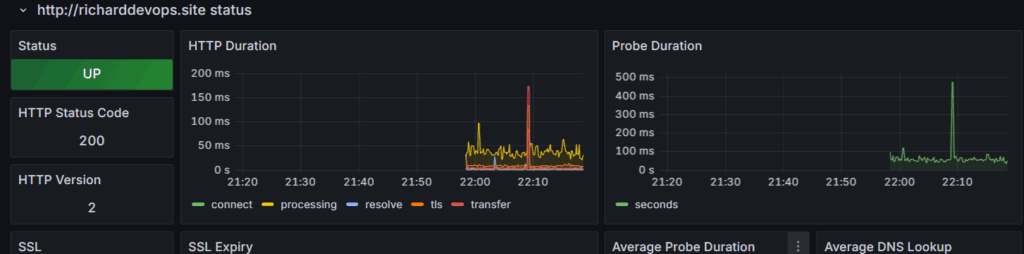
Hemos visto todas las piezas conectadas, desde el código en Github, la automatización con Jenkins, la seguridad con Trivy y sonarQube, los artefactos en Nexus, las imagenes en Docker Hub, la infraestructura con Terraform, el despliegue con AWS EKS y la observabilidad con Prometheus y Grafana.